一致性算法
CAP
(一致性算法、分布式事务)与CAP是属于分布式系统中设计和理念的两个概念;一致性算法通常会舍弃一定的可用性,保证了各节点数据的一致性
- 一致
- 可用
- 分区容忍
- 因为涉及到了不同服务器上的数据一致性,处于不同网络中的服务器,一定会遇到p(分区容忍性),这里就涉及到是否要让他继续提供服务。在CA中做抉择;
- 结合一致性算法章节一起看
- 结合分布式事务章节一起看
paxos
Paxos算法解决的问题是一个分布式系统如何就某个值(决议)达成一致 典型的场景 : 在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点执行相同的操作序列,那么他们最后能得到一个一致的状态
角色
- proposer : 提议者
- acceptr: 应答,参与者
- leaner: 接受者
两个阶段
- 阶段一
- proposer提出提案,向半数以上的accepter发送prepare的请求
- 如果一个accepter一个编号为N的prepare的请求,N比之前接收到的所有请求都大,之后就不接接受小于N的propose
- 阶段二
- propose接收到半数以上的accepter的yea,向他们发送accept
- accepter接收到针对编号N的accept的请求,如果我没有对大于N的propose做出响应,那么我就接受这个accept
ZAB 原子广播协议 ---- 在ZK.md有介绍,类似于paxos
RAFT
raft 把算法流程分为三个子问题:选举(Leader election)、日志复制(Log replication)、安全性(Safety)三个子问题
角色
- leader
- follower
- candidate raft在正常运行下,只有lead和follow;candidate 只有在选举的时候存在,选举成功过变为leader或者follower
周期任职
在 Raft 中使用了一个可以理解为周期(第几届、任期)的概念,用 Term 作为一个周期,每个 Term 都是一个连续递增的编号,每一轮选举都是一个 Term 周期,在一个 Term 中只能产生一个 Leader;当某节点收到的请求中 Term 比当前 Term 小时则拒绝该请求。
选举
定时选举器
- 启动后,定时器触发,向其他的节点请求vote,超过半数承认,变为candidate,向其他节点发送heartbeat
- 当在其间收到其他节点的requst判断term,偌比我大变为follow,如果比我小,忽略
- 如果选举超时,则增加term任期重新调整选举
- 在一个 Term 期间每个节点只能投票一次,
- 问题:所以当有多个 Candidate 存在时就会出现每个Candidate 发起的选举都存在接收到的投票数都不过半的问题,这时每个 Candidate 都将 Term递增、重启定时器并重新发起选举,由于每个节点中定时器的时间都是随机的,所以就不会多次存在有多个 Candidate 同时发起投票的问题
- raft接收到事务处理流程,
- 当为follow收到事务消息的时候会将消息转发给leader
- leader将消息添加到本本地日志
- 向follow通过heartbeat将消息发送给follower
- 接收到超过半数的ack
- 将消息存储本地磁盘
- 在下一个heartbeat中将消息通知follow,让follow将消息记录到本地
安全性
安全性是用于保证每个节点都执行相同序列的安全机制 问题: Follower 在当前 Leader commit Log 时变得不可用了,稍后可能该 Follower 又会倍选举为 Leader,这时新 Leader 可能会用新的Log 覆盖先前已 committed 的 Log Safety 就是用于保证选举出来的 Leader 一定包含先前 commited Log 的机制 选举安全性(Election Safety):每个 Term 只能选举出一个 Leader
quorum(法定人数)
概念:是指在分布式系统中进行读写操作所需的最小节点数或副本数;Quorum的概念用于决定何时认为一个操作在系统中已经达到了一定的一致性水平。
- 在常见的一致性算法中,例如Paxos和Raft,通常使用多数投票作为Quorum机制。假设有N个副本,那么Quorum可以定义为N/2+1,即超过一半的副本数;--- ZAB也是
- 使用Quorum机制可以提供分布式系统的强一致性保证:当进行读操作时,需要从至少一个Quorum中获取数据,以确保读取到的是最新的数据。而在写操作时,需要将数据写入至少一个Quorum中,以确保数据被复制到足够多的节点上,从而防止数据丢失。
- Quorum的大小可以根据系统的需求和可用性目标进行调整。较大的Quorum大小可以提供更高的可用性和数据冗余,但可能会增加延迟和网络负载
raft 与 ZAB
相同点
- 使用quorum
- 由leader发起写操作
- 用心跳检测保活
- 选举采用先到先投票的方式
不同点
- zab用的是 epoch 和 count 的组合来唯一表示一个值, 而 raft 用的是 term 和 index
- zab 的 follower 在投票给一个 leader 之前必须和 leader 的日志达成一致,而 raft 的 follower则简单地说是谁的 term 高就投票给谁
- raft 协议的心跳是从 leader 到 follower, 而 zab 协议则相反;zab由小弟来监听我
- raft的数据只有从leader到follow的份,raft不需要follow的数据
- zab 在发现阶段会先去同步最新的follow的数据,将自己的数据更新为quorum中最新的数据(这里保证了被丢弃的消息不能重现)。然后再去同步所有的follow的数据让所有的follow日志log保持一致(保证已经处理的消息不能丢失)
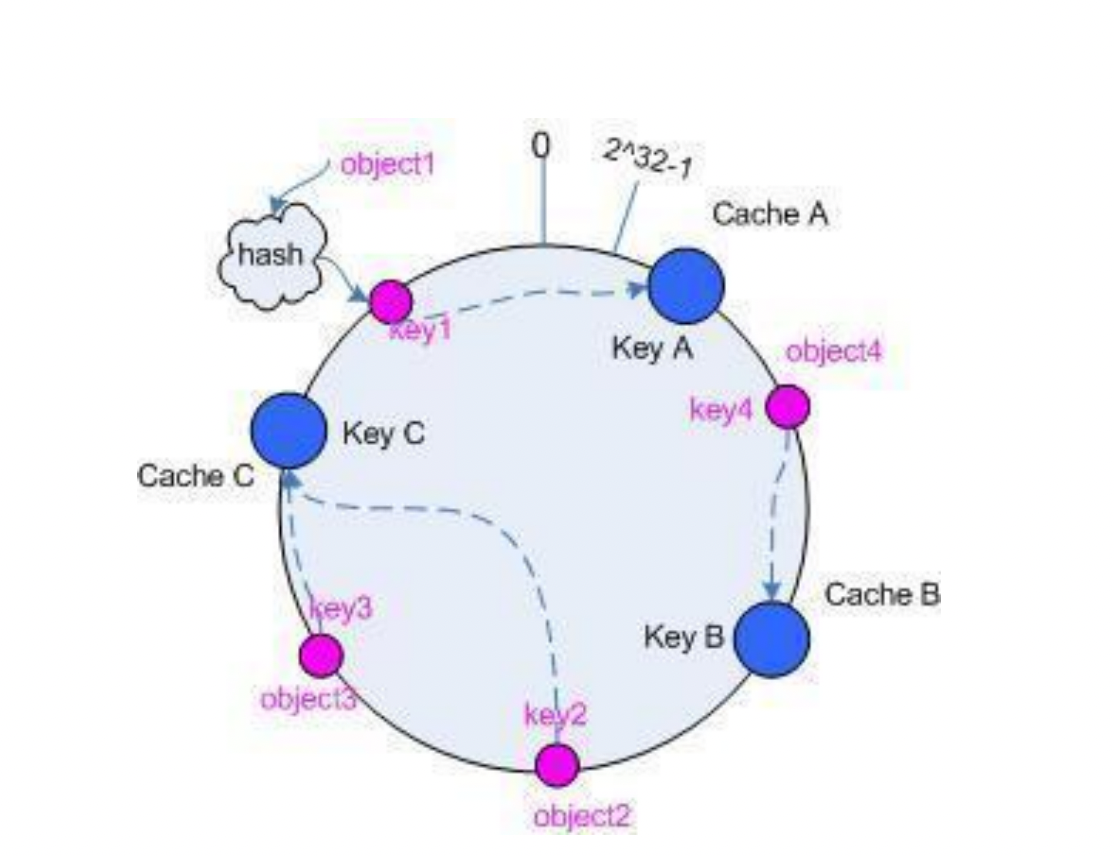
一致性hash Consistent hashing
- 构建圆形的hash空间
- 通常hash算法将value映射到32位的key值;,也即是 0~2^32-1 次方的数值空间,所以构建1个圆
- 把需要缓存的内容(对象)映射到 hash 空间
- 接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布
- 把服务器(节点)映射到 hash 空间
- 基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的 hash 算法
- 现在服务节点和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,首先确定对象hash 值在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
这里设计一个虚拟节点: 场景: 当服务器节点过少,不能均匀部署在hash环上 一个节点复制多个虚拟节点,映射在环的不同的位置
是为了解决分布式缓存的问题:比如一个key被hash以后到底存到那个服务器;通过hash环可以确定服务器从而找到key