io学习流程
用户态 & 内核态
内核态:内核本质是一种软件,控制计算机的硬件资源,并提供上层环境 用户态:上层应用程序活动空间,应用程序的执行要依赖于内核提供的资源,(包括cpu资源,存储资源,io资源) 两者关系:用户态的程序要访问内核态的资源可以通过:系统调用 系统调用 : 通过库函数及shell脚本进行封装,屏蔽复杂的底层实现细节,对系统调用进行封装提供简单接口给用户 从用户态到内核态的其他种系统调用 1. 系统调用 2. 异常:缺页异常,被动切换 3. 外设中断:外设完成用户请求以后,会通知cpu发送中断信号。cpu会暂停即将执行的命令进而处理外设中断请求
五种io网络模型
阻塞io(bloking io)
举例子: 内核空间 -> 线程A -> 线程B ->线程C (工作队列)
当线程A要进行网络传输创建socket语句的时候,此时由文件管理系统创建一个由其管理的socket对象,这个对象包含发送缓冲区,接收缓冲区,等待队列;其中等待队列指向所有等待socket事件的线程
当线程执行到recv的时候,那么线程A就会移动到等待队列之后,此时工作队列没有线程A,所以线程A就不会占用cpu,而cpu轮训执行也只会执行线程BC
应用进程调用recvform,执行系统调用,直到有数据报被拷贝到应用进程才返回,否则进程一直处于阻塞状态。此时会把cpu给交出去不会一直占用
非阻塞IO(non-blocking IO)
用轮询的方式一直请求内核看数据有没有拷贝完,所以非阻塞io不会释放cpu会一直轮询,造成cpu浪费
信号驱动式IO(signal-driven IO)
应用程序使用套接字进行信号驱动I/O,通过sigaction系统调用安装一个信号处理函数,用户进程运行不阻塞,当数据准备好以后,内核会发出一个sigio信号给信号处理函数,信号处理函数调用io操作处理数据。 缺点:信号IO在有大量的io操作的时候,会因为信号队列的溢出导致没法通知
异步IO(asynchronous IO)
io多路复用是将文件的句柄的状态通知给用户线程,由用户自行读取数据处理数据,异步io是数据内核已经处理完了,并且放在用户线程的指定的缓冲区域,当用户线程得到通知后可以直接使用数据;
多路复用IO
概念1:多路分离函数select 1. 解决非阻塞io轮训的问题 2. 系统内核提供多路分离函数select 3. 用户将socket注册到select上 4. 阻塞等待select的反馈 5. 数据到达后,select被激活 6. 用户发起read将数据从内核拷贝到用户空间处理 1. 涉及问题:内核数据拷贝的问题 7. 一个线程可以注册多个socket,可以用一个线程不断的调用select读取被激活的socket,从而达到一个线程读取多个socket场景(处理多个io)
- 但是还是阻塞的,阻塞在select函数,有没有什么办法让多路复用不被阻塞
引出概念2: reactor下的io多路复用 1. 用户线程注册到reactor上,然后reactor负责调用内核的select函数检查socket 2. 当有socket被激活后通知其对应的用户线程(回调 3. 所以这样情况下用户线程不会被阻塞,因为用户线程要处理io的时候,数据已经到达了
- 优点:单个线程可以处理多个网络接连io,原理在于不再又应用程序监听链接,而是由内核替代应用程序监听文件描述符; 举例:
- 用户调用select,整个进程会阻塞(这里需要看一下)
- 内核会监听select负责的socket,当有一个socket的数准备好,select就会返回,
- 然后用户在进行read操作,将数据从内核到用户区
io多路复用中的select poll epoll函数介绍: 1. 这些机制主要做的是一个任务是监听多个描述符,一旦某个描述符就绪,就通知对应的程序进行对应的读写操作 2. 但是收到通知以后还是线程自己去内核进行读取,而异步io实现会把数据从内核考到用户空间
select : 1. 监视三类文件描述符:writefds;readfds;exceptsfds; 2. 调用select函数会阻塞 3. 当select返回遍历查看那个描述符操作完成 4. 缺点:最大只能监听1024个描述符 5. 实时性好,可以精确到微秒,而其他两个只能精确到毫秒,可移植性比其他两个好 6. select:1024/ 微秒/ 轮训fd
poll : 1. 与select的区别在于没有最大的描述符监听限制 2. 同样准备完成后需要调用pollfd轮训获取就绪的描述符、 3. 随着描述符监听的增加,效率会降低很多 4. 实时性没有select好 5. poll:/ 轮训fd/ 毫秒/ 无上限
epoll : 1. epoll_creat():告诉内核监听的数目有多大,不是限制只是内核初始分配的建议,但是内核会占用这些描述符,所以使用完了,必须要关闭掉 2. epoll_ctl(): epfd : epoll_creat的返回值 ;op:三个宏来表示:添加,删除,修改 fd:要监听的fd(文件描述符);epoll_event:告诉内核需要监听什么事 3. epoll_wait():等待epfd上的io事件,最多返回maxevents个事件; 4. 只能运行linux平台,有大量描述符需要同时轮训,并且这些连接最好是长连接 5. 如果同时监控的描述符太少少于1k,不需要用epoll,不能体现其优势 6. 描述符的状态变化多,并且短暂不好使用epoll,epoll描述符都在内核中,每次对描述符的状态改变都要通过epoll_ctl()进行系统调用,频繁的系统调用导致效率降低 7. epoll:无上限,无需轮训,类似信号量,将就绪存在队列中,----- 通过epollwait直接返回就绪句柄,无需轮训fd
讲一下什么Reactor 和 Proactor
Reactor包含如下角色: 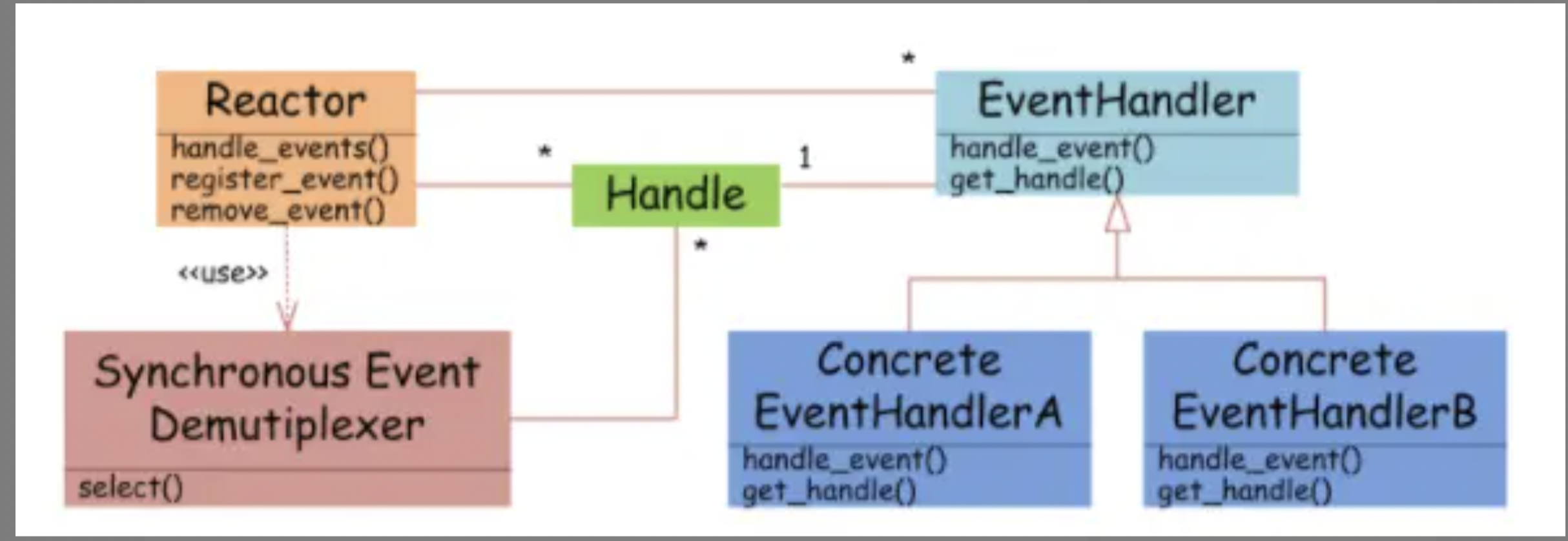
- Handle 句柄: 用来标识socket连接或是打开文件;
- Synchronous Event Demultiplexer:同步事件多路分解器:由操作系统内核实现的一个函数;用于阻塞等待发生在句柄集合上的一个或多个事件;(如select/epoll;)
- Event Handler:事件处理接口,拥有io文件句柄(可以通过get_handle获取,以及对handle的操作handle_event(读/写))
- Concrete Event HandlerA:实现应用程序所提供的特定事件处理逻辑;
- Reactor:反应器,定义一个接口,实现以下功能:
- 供应用程序注册和删除关注的事件句柄;
- 使用handle_events运行事件循环;
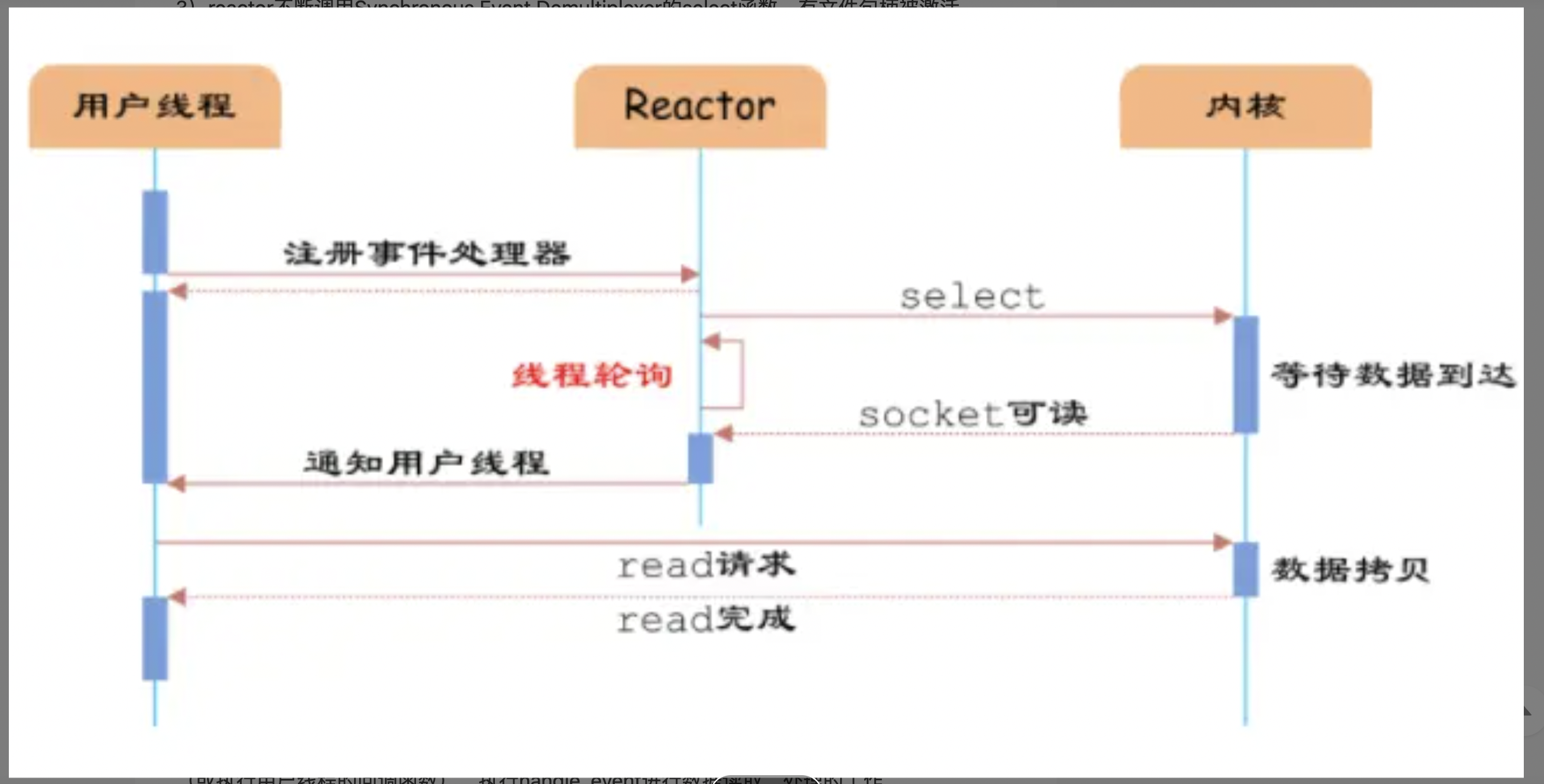
- reactor不断调用Synchronous Event Demultiplexer的select函数,有文件句柄被激活,select就会返回,handle_events会调用与文件句柄关联的事件处理器handle_event进行处理
io多路复用的流程方式:
1. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理
2. 用户线程注册事件处理器之后可以继续执行做其他的工作(异步)
3. 而Reactor线程负责调用内核的select函数检查socket状态。
4. 当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数)执行handle_event进行数据读取、处理的工作。[label](c:/Users/Raytine/Desktop/1.JPG%0D) 
因为select系统调用是阻塞的,所以io多路复用并不是真正的异步,只能称为异步阻塞io
单线程模式异步非阻塞io
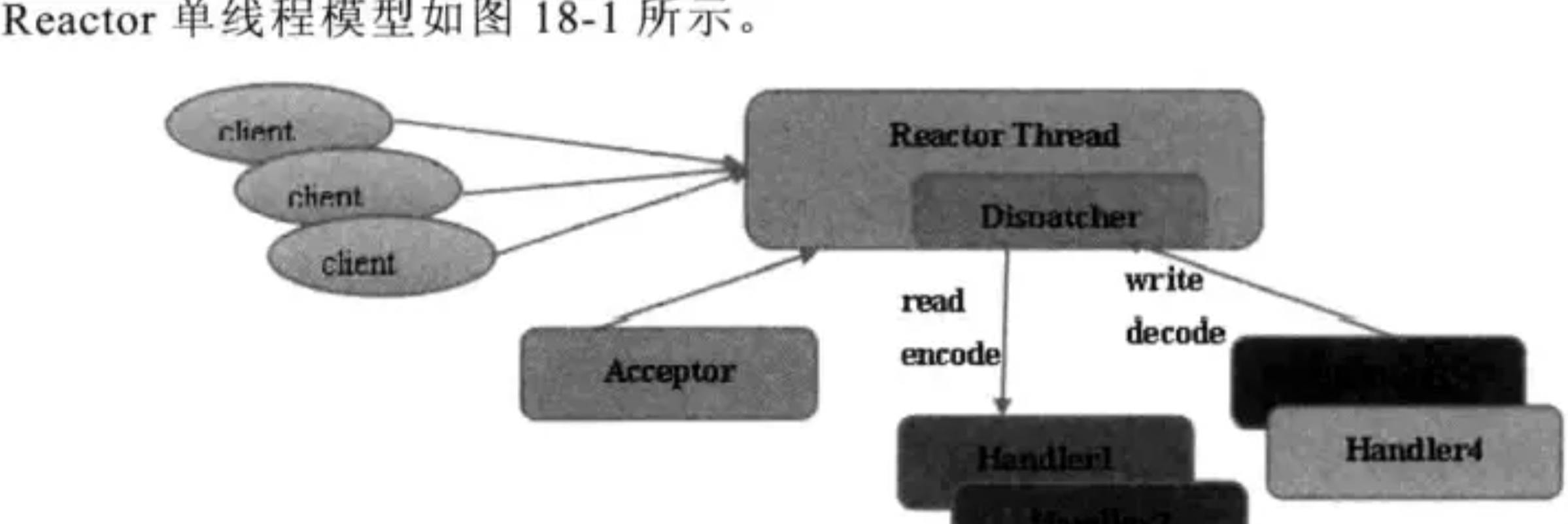 acceptor收到了客户端的tcp的链接。建立成功后,通过dispatch将对应的bytebuf分发到指定的handler上,进行消息解码 问题:
acceptor收到了客户端的tcp的链接。建立成功后,通过dispatch将对应的bytebuf分发到指定的handler上,进行消息解码 问题:
1. 一个nio线程无法处理太多的链接,即便cpu满负荷也不可以 2. nio负载过重,处理速度会变慢 3. 一旦nio线程跑飞,整个系统的通信模块都会变得不可用
Reactor多线程模型
不同处: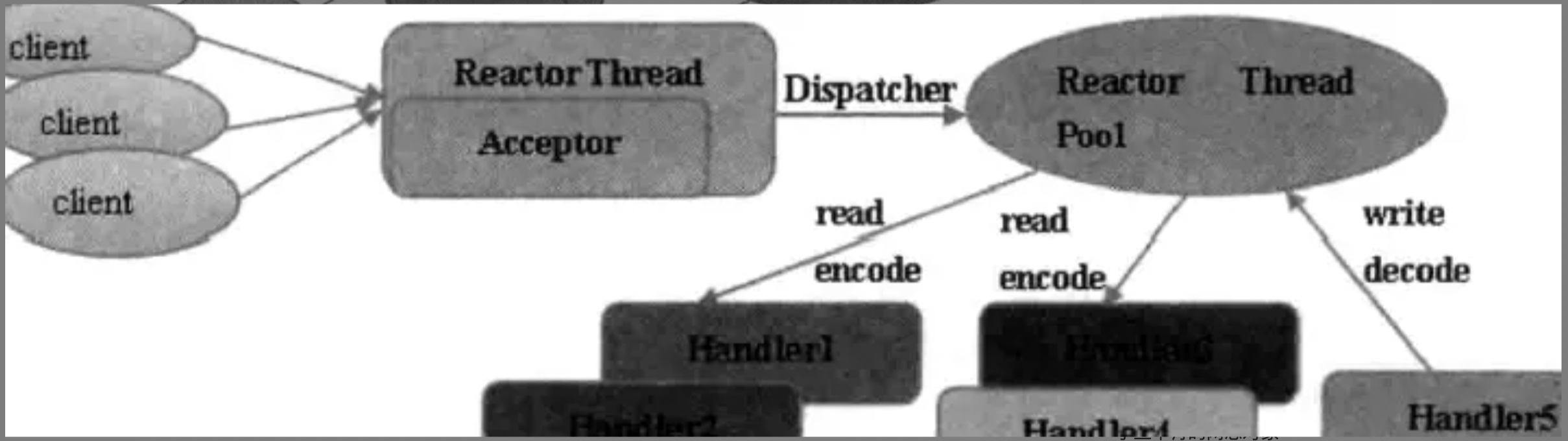
- acceptor作为一个单独的nio线程监听服务端,接收client的request
- 网络io操作读写由一个nio线程池负责,一个队列和多个可用的线程,这些线程负责消息的编解码及发送
- 一个nio线程可以同时处理多个链路,但是一个链路只对应一个nio线程
主从Reactor多线程模型
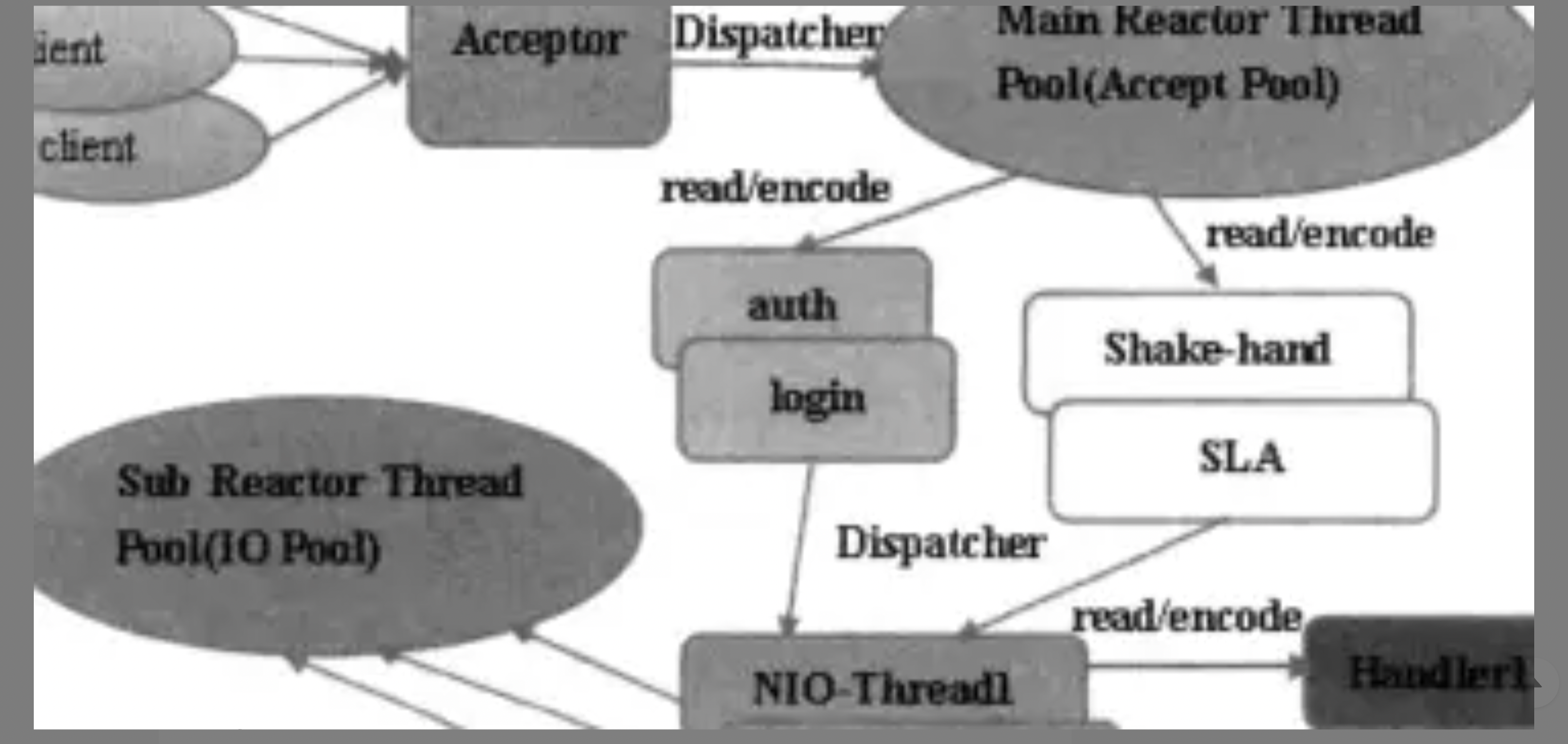 最大的特点就是接收客户端连接的不是一个单独的nio操作而是变成了一个独立的nio线程池
最大的特点就是接收客户端连接的不是一个单独的nio操作而是变成了一个独立的nio线程池
- 这个接收线程池收到请求并处理完以后会创建一个新的socketchannel然后注册到sub线程池的io上
- 然后由sub线程池中的对socketchannel中的数据进行编解码操作
总结:acceptor线程池仅仅用于客户端的登录握手等安全认证,建立成功以后就将链路注册到后端的subReactor线程池的io线程上,由io线程负责后续的io操作
Proactor: 主要区别一句话总结: reactor是内核告诉用户进程文件句柄状态,用户线程去内核去进行读取及处理数据的操作;proactor是内核将数据读取完,并且将内核中的数据复制到用户线程指定的缓存区域,告诉用户线程直接去处理。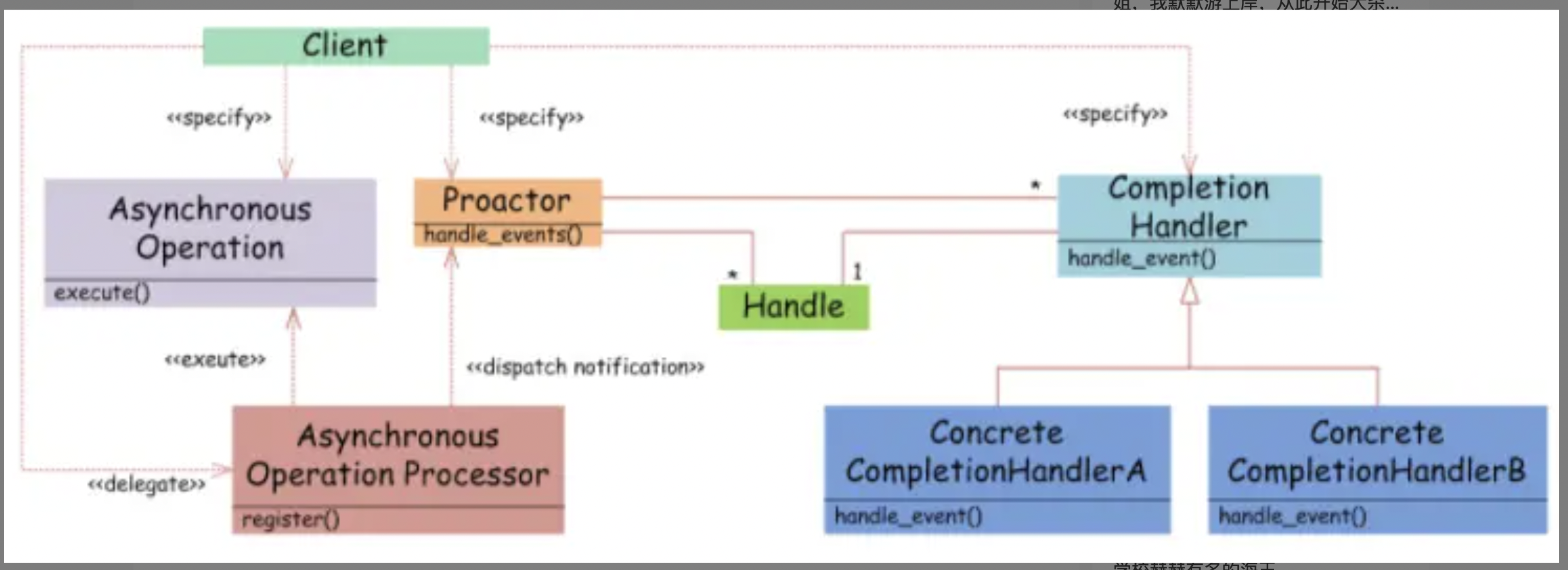
- Handle 句柄;用来标识socket连接或是打开文件;
- Asynchronous Operation Processor:异步操作处理器;负责执行异步操作,一般由操作系统内核实现;
- Asynchronous Operation:异步操作
- Proactor:主动器;为应用程序进程提供事件循环;从完成事件队列中取出异步操作的结果,分发调用相应的后续处理逻辑;
- Completion Handler:完成事件接口;一般是由回调函数组成的接口;
- Concrete Completion Handler:完成事件处理逻辑;实现接口定义特定的应用处理逻辑;
- 大致流程:
- 用户线程将 完成接口处理的接口 注册到 异步操作处理器
- 异步操作处理器会开启独立的内核线程执行异步操作
- 操作结束以后处理器会将complehandler和处理完的io数据一起给Proactor
- 由proactor调用不同的完成事件接口的handle_event()
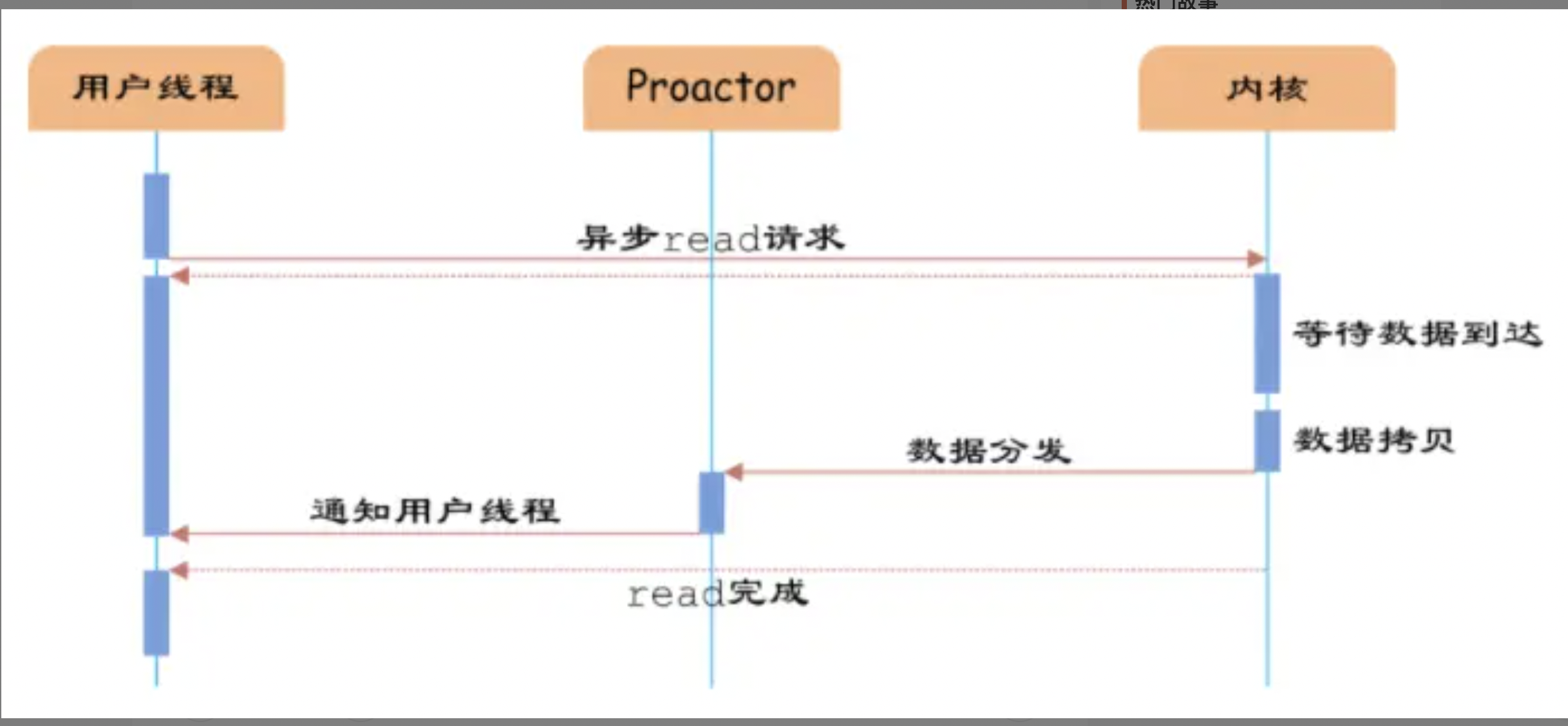
过程:用户线程直接调用proactor提供的异步api进行read请求,就是完成上面的注册过程。 1. 当read请求的数据到达时,由内核负责读取socket中的数据,并写入用户指定的缓冲区中。 2. 最后内核将read的数据和用户线程注册的CompletionHandler分发给内部Proactor,Proactor将IO完成的信息通知给用户线程
零拷贝
指计算机在执行操作的时候,cpu不需要先将数据从某处复制到一个特定地方,节省cpu的时钟周期和内存带宽 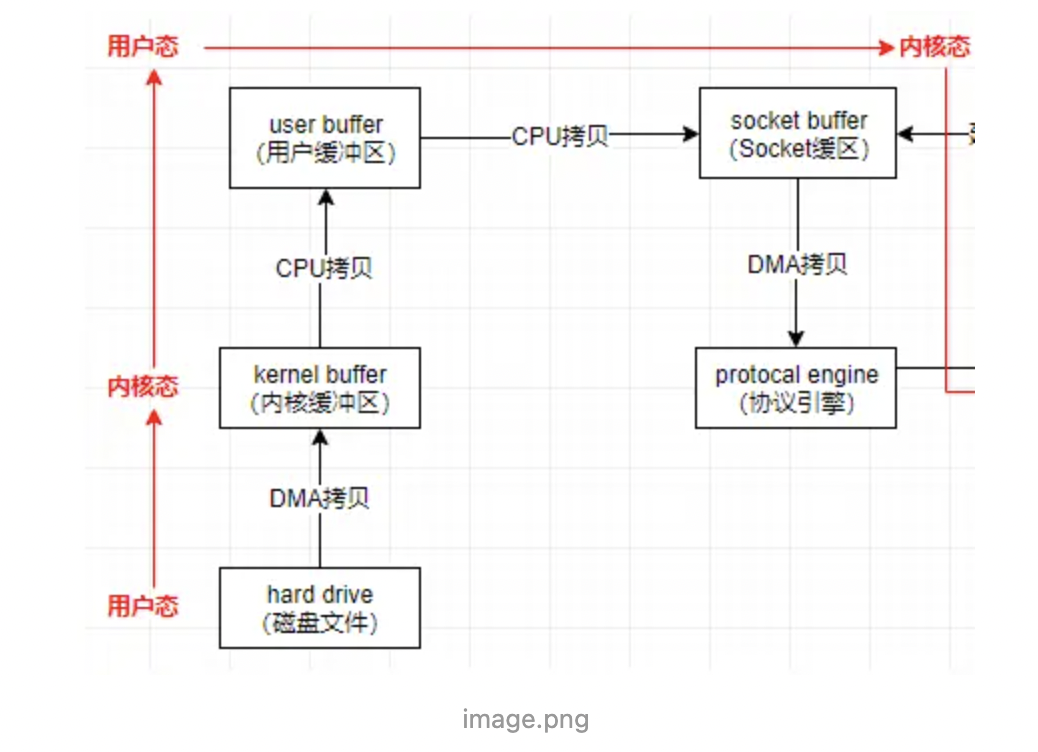
DMA
DIRECT MEMORY ACCESS 这个东西不消耗cpu 从磁盘到内核read缓冲区,从内核到网卡,两个操作都是DMA 
MMP
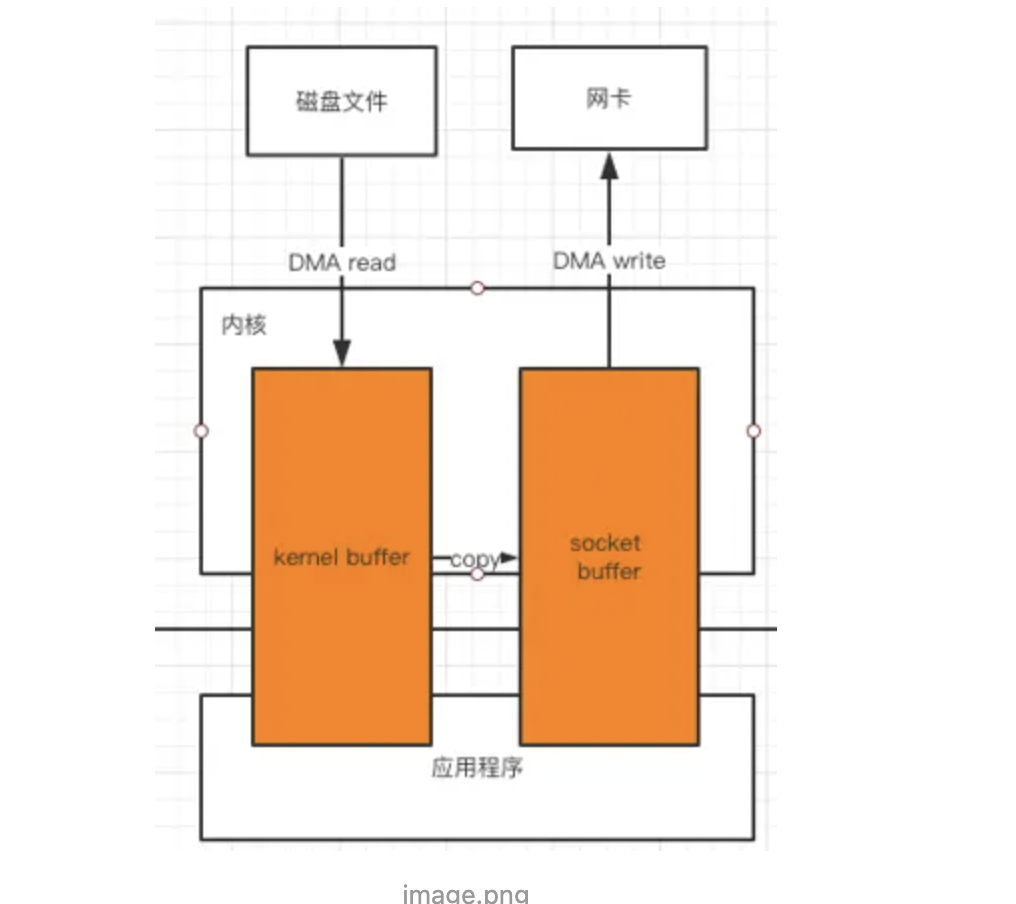
实现原理 使用虚拟内存替代物理内存(使用虚拟内存用户进程同样可以对文件内容可以操作) 节省了上图内核缓冲到用户空间以及用户空间到socket缓冲的拷贝流程:其中内核缓冲(磁盘读到的read缓冲区)到socket缓冲区(发往网卡的缓冲区);这两个缓冲区的拷贝没有节省,但是都发生在内核中,效率变快 使用 mmap 系统调用可以将用户空间的虚拟内存地址与文件进行映射(绑定),对映射后的虚拟内存地址进行读写操作就如同对文件进行读写操作一样
fileChannel 很重要两个零拷贝操作一个mmap对应filechannel的.map(),一个sendfile对应filechannel的.transferTo()
NIO的FileChannel.map底层就是封装了 linux的 mmap
public static void main(String[] args) {
File file = new File("");
try {
//打开FileChannel只能读取
FileChannel fileChannelIn = new FileInputStream(file).getChannel();
//打开FileChannel只能写入
FileChannel fileChannel1Out = new FileInputStream("").getChannel();
//读入数据转为MappedByteBuffer
MappedByteBuffer mbb = fileChannelIn.map(FileChannel.MapMode.READ_ONLY,0,file.length());
//创建解码器
Charset charset = Charset.forName("UTF-8");
//写入数据
fileChannel1Out.write(mbb);
mbb.clear();
//创建解码器
CharsetDecoder decoder = charset.newDecoder();
// 使用解码器将byteBuffer转为CharBuffer
CharBuffer charBuffer = decoder.decode(mbb);
System.out.println(charBuffer);
}catch (Exception e){
return;
}
}sendFile
保存了mmap的不需要来回拷贝的优点,适用于应用进程不需要对读取数据做任何处理的场景,类似于一种完全意义上的数据传输 这个实现的拷贝,主要做的实现了数据的偏移量offset,数据长度length的拷贝
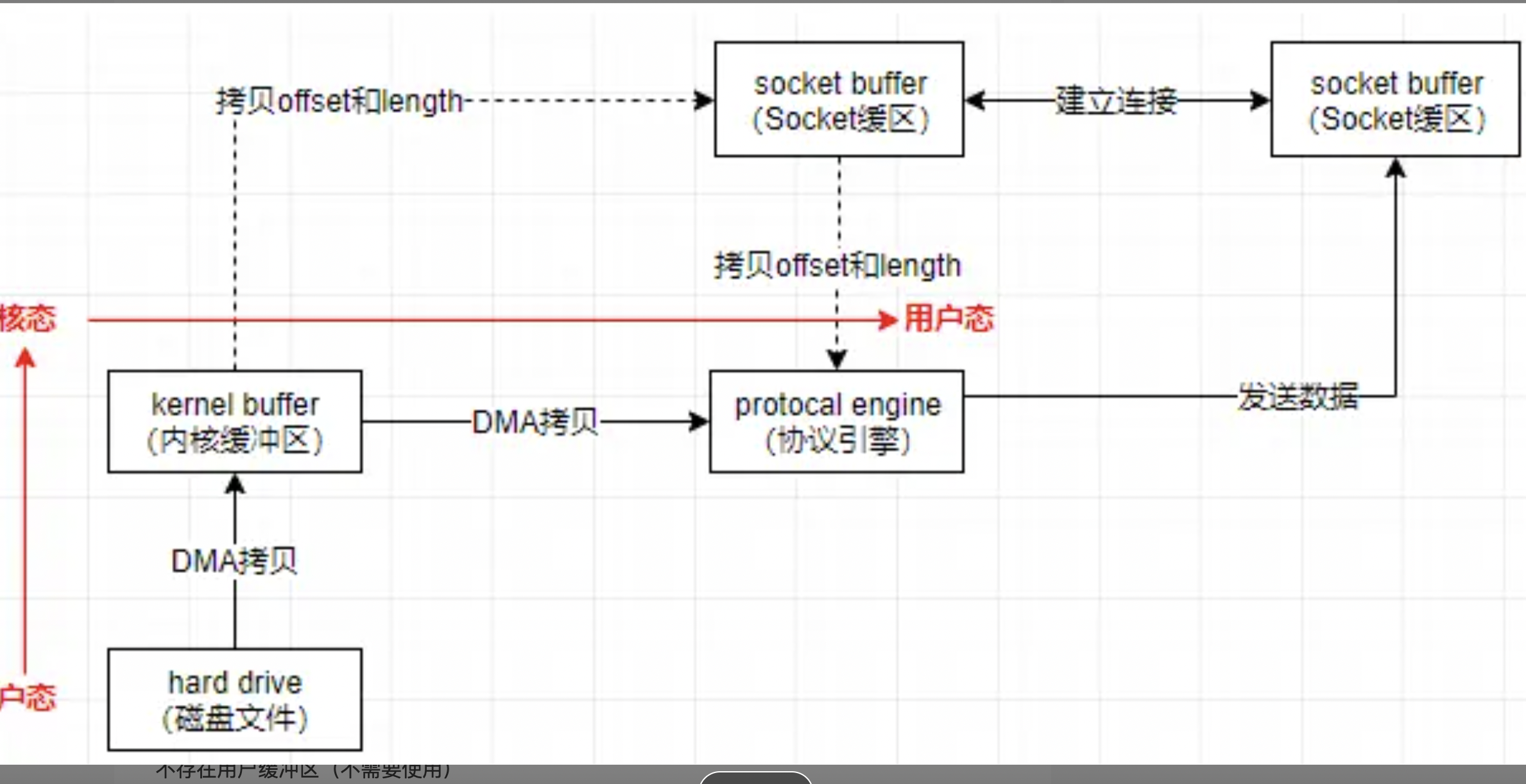 看似不经历socket缓冲区,比mmp更减少了一步,从磁盘读完文件到内核read缓冲区,再DMA直接到了网卡,发送数据
看似不经历socket缓冲区,比mmp更减少了一步,从磁盘读完文件到内核read缓冲区,再DMA直接到了网卡,发送数据
不存在用户缓冲区(不需要使用) 数据甚至不用从内核缓冲区拷贝到socket的缓冲区,只需要将内核缓冲区的拷贝一些offset和length到socket缓冲区nio中使用的是FileChannel.transferTo,底层封装的是linux的sendfile这个方法
public static void main(String[] args) {
String files[] = new String[1];
files[0] = System.getProperty("usr.dir") + "/c:\\aa\\dn.txt";
catFiles(Channels.newChannel(System.out), files);
}
private static void catFiles(WritableByteChannel target, String[] files) {
try{
for (int i = 0; i < files.length; i++) {
FileInputStream fileInputStream = new FileInputStream(files[1]);
FileChannel channel = fileInputStream.getChannel();
channel.transferTo(0,channel.size(),target);
channel.close();
fileInputStream.close();
}
} catch (Exception e){
System.out.println(e);
}
}总结:
- 传统io有4次上下文切换,4次拷贝 磁盘 -> 内核read -> 用户 -> 内核socket -> 网卡(协议引擎)
- mmap:三次拷贝(两次DMA + 一次内核read缓冲到内核socket缓存)。将磁盘文件映射到内存,支持读写内存文件直接反映到磁盘文件上,适合小文件读取
- sendfile:两次拷贝(两次DMA),适合大文件传输
netty 的零拷贝
ByteBuf和ByteBuffer都是用于处理字节数据的缓冲区,但它们来自不同的Java库,并且有一些区别。
Netty的接收和发送ByteBuffer采用的是Direct buffers,使用堆外内存直接进行socket读取
重要的是Unpooled 的工具类,既可以将多个缓冲区重组又可以将1个缓冲区切分(wapper和slience)
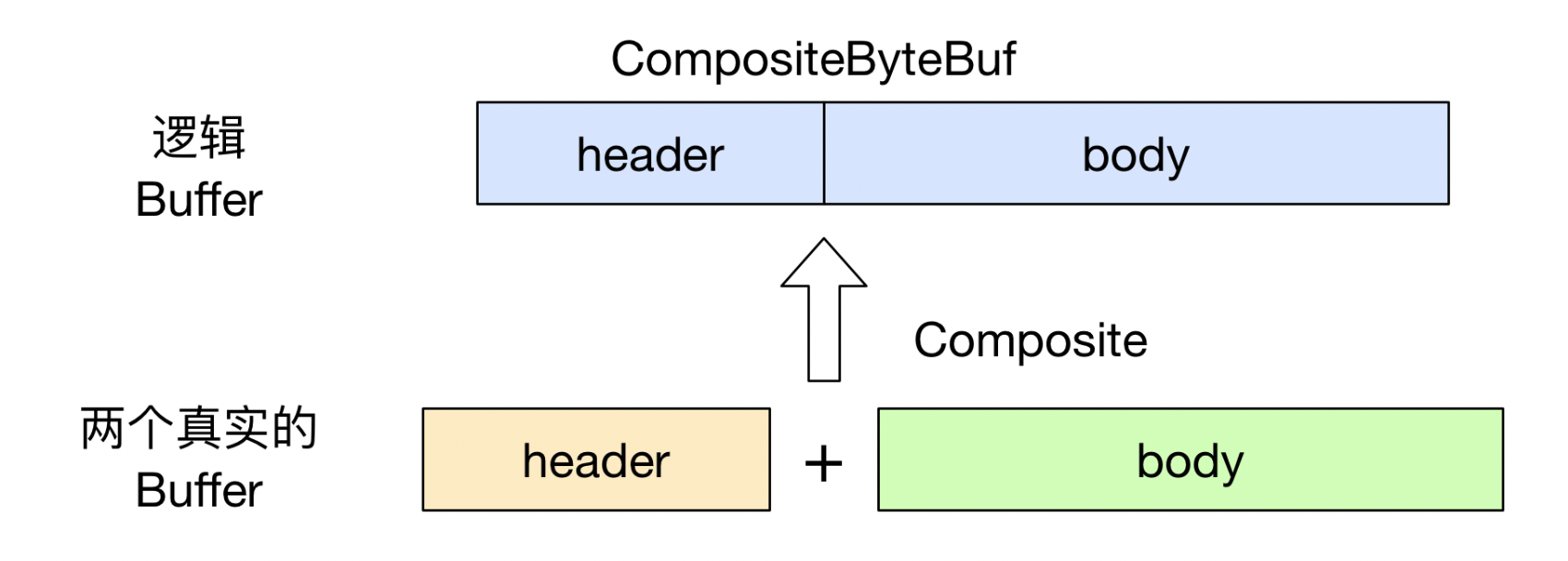
CompositeByteBuf对组合的buffer进行操作 :ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝
文件传输采用transferTo,使用DefaultFileRegion类进行了一个封装
通过 wrap 操作:我们可以将 byte[] 数组、ByteBuf、ByteBuffer等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作.
- byte 数组, 我们希望将它转换为一个 ByteBuf 对象
javabyte[] bytes = ...; ByteBuf byteBuf = Unpooled.buffer(); byteBuf.writeBytes(bytes);- 我们可以使用 Unpooled 的相关方法, 包装这个 byte 数组, 生成一个新的 ByteBuf 实例, 而不需要进行拷贝操作
javabyte[] bytes = ... ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);java// 将bytebuffer转换为bytebuf ByteBuf byteBuf = Unpooled.wrappedBuffer(byteBuffer);
Unpooled.wrappedBuffer(ByteBuffer)方法创建的ByteBuf实际上是一个ByteBuf的视图,与原始的ByteBuffer共享数据,因此在释放ByteBuf之前不应修改原始的ByteBuffer。
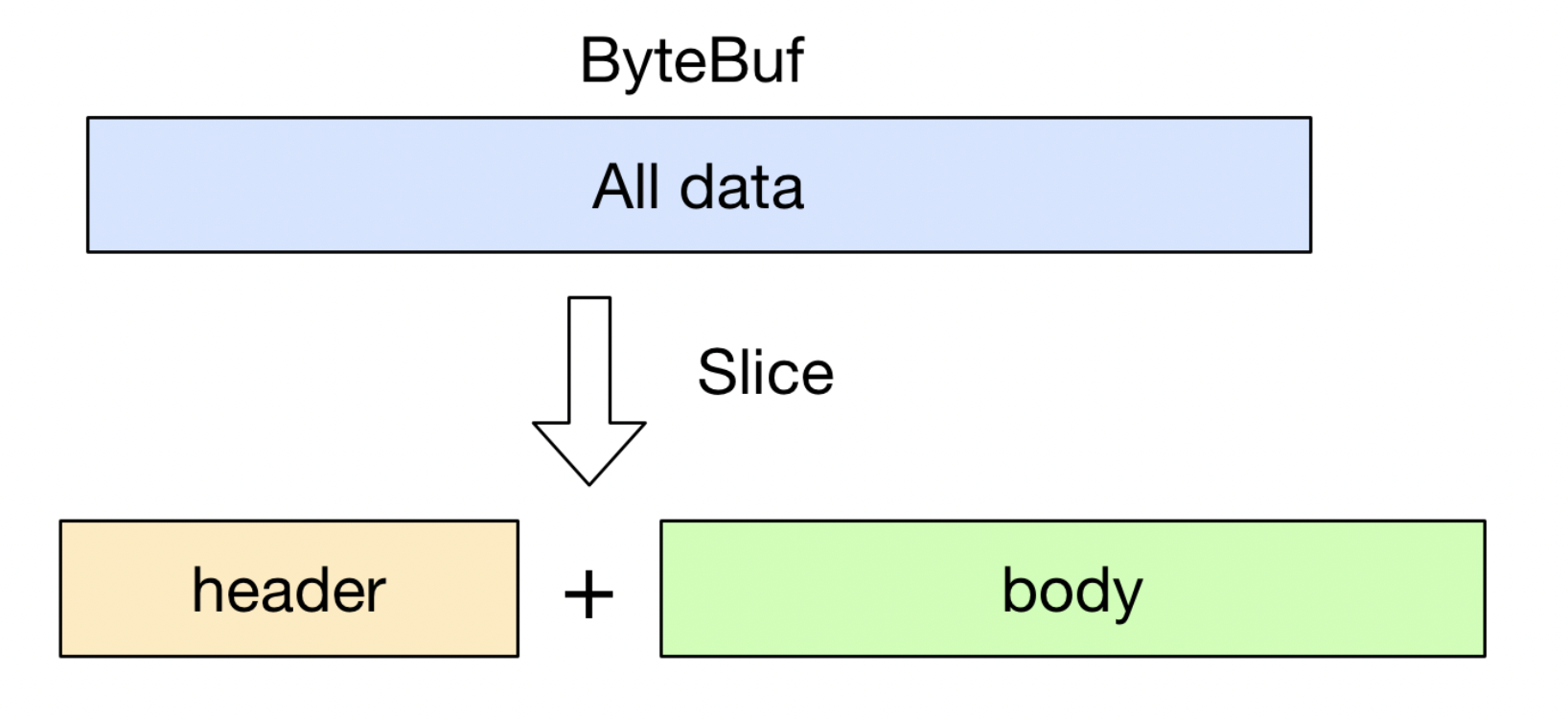
- slice 操作实现零拷贝
- slice 操作和 wrap 操作刚好相反;wrappedBuffer 可以将多个 ByteBuf 合并为一个, 而 slice 操作可以将一个 ByteBuf 切片 为多个共享一个存储区域的 ByteBuf 对象.
- 用 slice 方法产生 header 和 body 的过程是没有拷贝操作的, header 和 body 对象在内部其实是共享了 byteBuf 存储空间的不同部分而已.