随笔

- id 不重要: 查询的序列号
- select_type 不重要:查询类型:例子:SIMPLE:简单的select不使用union或子查询
- table 不重要:表明
- type 重要 :
- const :最多只有一行记录匹配,当联合主键或唯一索引的所有字段跟常量值比较时,join类型为const。其他数据库也叫做唯一索引扫描
- eq_ref / ref :相对于下面的ref区别就是它使用的唯一索引,即主键或唯一索引,而ref使用的是非唯一索引或者普通索引。
- fulltext: 理解为效率较差但优先级高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引。全文索引的优先级很高
- range: 索引范围查询,常见于使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN()或者like等运算符的查询中。
- index: 索引全表扫描,把索引从头到尾扫一遍
- all : 全表扫描
- key:真正用到的索引
- key_len : 查询用到的索引长度(字节数),多列索引,留下这个列的值,算一下你的多列索引长度就知道有没有使用所有的列
- key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
- rows: 这是mysql估算的需要扫描的行数
- extra 重要:
- distinct: select 中使用了distinct关键字
- using filesort: 表示mysql需要额外的排序操作,不能通过索引顺序达到排序效果,需要将其优化
- using index : 覆盖索引扫描。查询在索引树中就可以查找到所需要的数据,性能正常
- using temporary : 查询时候具有临时表
- ref列 :如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段
字节B: 位Bit: int 是 4个字节:32位 一次io操作是4k(字节) 为了将磁盘io控制在很小的数量级,选择一个高度可控的多路搜索树木 b+
b+树怎么优化查询
- io的次数取决于树的高度,假设高度h
- 表数据大小:N,每个磁盘块能存储的大小: M, 公式:h = log(m+1)N (m越大h越小)
- 每个磁盘块m = 磁盘块大小(固定4k/8k)/ 数据,所以磁盘块中的数据越小,磁盘块M越大,索引树越低
- 结论:
- 这就是为什么每个数据项,即索引字段要尽量的小
- 这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高
对于索引的优化
- 最左前缀匹配。(会一直从左向右直到遇到范围查找则停止)
- 我的条件是 a =1,b=1,c>1,d=1
- 如果复合索引为(a,b,c,d),索引走到c就停止了,d不会走索引
- 如果我的复合索引为(a,b,d,c),所有的都会走索引,因为查询优化器会给我自动优化
- =和in可以乱序 ,如上
- 索引列不能参与计算,保持列“干净” : from_unixtime(create_time) = ’2014-05-29’ 改为 create_time = unix_timestamp(’2014-05-29’)。
- 对索进行拓展而不是进行新建
- (重要)尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*):举例子唯一索引 算出来值为1;若为性别,只有男女情况下,基数大的场景下,这个就无限趋于0;就没必要建立索引
索引
物理存储角度:非聚簇索引,聚蔟索引
逻辑角度 主键索引,非主键索引,复合索引,唯一索引
查询回表怎么回事
流程
- mvcc作用于读已提交,可重复读 (undolog /版本链 /readview)
- 所有的undolog通过回滚指针相连,共同组成版本链
- 此处不完全正确
- 版本链 = undolog(包含回滚指针) + record(原始数据)+ 事务id
- 对数据进行修改时不会直接覆盖数据而是会通过增加undolog的方式方便回滚
- readview
- 一个快照,存储当前活动的事务id(即未提交的事务),排序生成一个数组
- 使用方式
- 找到一条记录,找到该记录中当前的事务id,对比readview中该id所处的位置,如果该id在readview的最左边,说明该事务已经提交可以读取,若在右边,说明未提交,根据undolog中的回滚指针(roll-pointer)找到上一个版本,继续比对版本中事务id所处readview中的位置
- 如果处于该事务ID在readview最小和最大事务id之间,如果该id在readview中则不可以访问(表示该事务还没有提交,此时要沿着版本连向上找),如果id不在版本链中则可以访问
- 举例子:
- 事务id为2;版本链子是(1.3.4);这个时候就可以访问
- 所有的undolog通过回滚指针相连,共同组成版本链
- mvcc只会在RC和RR级别使用
- RC中:每次执行读操作时都会创建一个新的ReadView;因为读取的数据是读已提交,所以需要知道当前已经提交的事务
- RR中:
- 为了保证在整个事务中保证事务的一致性,第一次执行事务时候会创建readview,在该事务的处理期间,使用同一个readview,这样可以保证规避不可重复读的场景
- 幻读:其他事务在我的事务执行期间对查询范围插入行,RR中readview是固定所以其他事务在事务执行期间不能在查询范围内插入新的行,从而避免了幻读的问题。
- 间隙锁(Gap Lock)是一种为了防止幻读而设计的特殊锁形式,它在RR隔离级别下使用,但它仅是MVCC机制的一部分。间隙锁用于锁定索引记录之间的间隙,以防止其他事务在这些间隙中插入新的行;实际上它同时锁定索引记录之间的间隙和索引记录本身
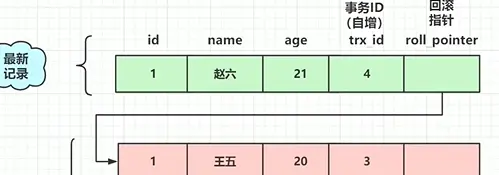
场景:  理解一下:当出现update以后,会进行readview的更新,所以B第二次读取不是沿用一开始的版本链,而A没有更新操作,读取一直读的是当前的版本链就实现了可重复读
理解一下:当出现update以后,会进行readview的更新,所以B第二次读取不是沿用一开始的版本链,而A没有更新操作,读取一直读的是当前的版本链就实现了可重复读
当前读与快照读
当前读:在当前读(current read)的情况下,当前读,读取的是记录的最新版本,并且会对当前记录加锁,防止其他事务发修改这条记录。MySQL通过next-key lock来避免幻读。 一种是要加锁的特殊的读操作,它读的是记录的最新版本。
- -- 共享读锁
- select * from table where ? lock in share mode;
- -- 共享写锁
- select * from table where ? for update;
- -- 增删改也属于当前读,因为要先看这条记录在不在
- insert into table values (…);
- update table set ? where ?;
- delete from table where ?;
快照读:MVCCMySQL通过MVCC(多版本并发控制)来避免幻读。读取的是记录的可见版本 (有可能是历史版本),不用加锁。
场景
RR级别下;
- 场景一:
- T1: select * from where id >100 <200;
- T2 : insert 150;(T1属于快照读所以不影响T2的插入)
- T1 select
- T1两次查询不会变更,解决幻读,insert可以插入;因为mvcc,readview只有第一次select生成的
- 场景二:
- T1: select * from where id >100 <200 for update(重点)
- 出现了for update说明要快照读,这时候对结果进行间隙锁
- T2 : insert 150;
- 插入阻塞,事务1没完成不会插入
- T1 select 解决幻读
- T1: select * from where id >100 <200 for update(重点)
- 场景三
- T1: select * from where id >100 <200;
- T2 : insert 150;
- T1 update t1 set name = ’11‘;(出现当前读,更新readview)
- T1 select * from where id >100 <200;
- 此时出现了150,幻读了 原因:: RR级别下ReadView的生成时机是在事务中的第一次查询,事务结束前该ReadView复用。但是如果事务中进行了当前读的操作,比如例3事务一中的update,后续再查询就会重新生成ReadView。也就是说update操作产生了当前读,那当前读肯定可以读到事务2已经提了的数据,然后全部更新后再去读就又会产生一个readview,很明显之前的update操作对于这个readview是可见的,所以数据的条数变成最新的了 所以RR级别在快照读的场景下通过mvcc保持一个readview的场景下保证了不会出现幻读,而快照读通过加锁的方式保证了数据不会更改保证了幻读的产生;至于场景三属于异常场景由最初的事务产生当前读导致readview更新导致
慢sql优化
- 看是否业务不可接受,设置sql——no——chache
- where条件单表查,看那个条件区分度最高
- explain看执行计划
- order by limit 形式的sql语句让排序的表优先查!!
- 了解业务方使用场景
- 加索引
四种事物隔离级别
- 读未提交
- 未提交的事务也可以读取,基本没有数据库用
- 读已提交
- 已经提交的事务可以进行读取;一个事务要等到另一个事务提交后才能读取数据 -》oracle,sqlserver
- 可重复读
- 即开始读取数据(事务开启)时,不再允许修改操作 -》 mysql
- 串行读
- 脏,不可重复,幻读都不会出现
脏读:未提交的事务被读取,只有在读未提交时候才会出现 一个事务读取另一个未提交的数据。 
不可重复读 一个事务范围内两个相同的查询却返回了不同数据。 主要影响的是update操作,只有等update完成以后才能进行读取,在读已经提交时候最后出现(再升级就不可见) 
幻读 主要影响是insert操作,也是一个事务范围内,两次查询返回了不同的数据 
什么是 redo 和 undo 日志 什么是binlog??
binlog
- 二进制日志,用于主从数据同步,数据恢复
- Statement-Based Replication (SBR) - 基于语句的复制
- Row-Based Replication (RBR) - 基于行的复制
- Mixed-Based Replication (MBR) - 混合模式复制: 这是上述两种模式的混合形式。MySQL会根据实际情况自动选择使用SBR或RBR来记录Binlog。
- 在RBR模式下,因为它需要记录更多的详细数据,会占用较大内存
binlog如何刷盘
- 对于InnoDB存储引擎而言,只有在事务提交时才会记录binlog,此时记录还在内存中,那么binlog是什么时候刷到磁盘中的呢?
- 通过sync_binlog参数控制binlog的刷盘时机,取值范围是0-1-N
- 0:不去强制要求,由系统自行判断何时写入磁盘
- 1:每次commit的时候都要将binlog写入磁盘;
- MySQL 5.7.7之后版本的默认值
- N:每N个事务,才会将binlog写入磁盘。
redolog
- inndb为了支持事务持久性,设计出的日志文件
- 解决了事务持久化和刷盘的频次问题
- 具体来说就是只记录事务对数据页做了哪些修改
redolog基本概念
- redo log包括两部分:
- 一个是内存中的日志缓冲(redolog buffer),
- 另一个是磁盘上的日志文件(redolog file)
- mysql每执行一条DML语句,先将记录写入redolog buffer,后续某个时间点再一次性将多个操作记录写到redolog file。这种先写日志,再写磁盘的技术就是MySQL里经常说到的**WAL(Write-Ahead Logging)**技术。
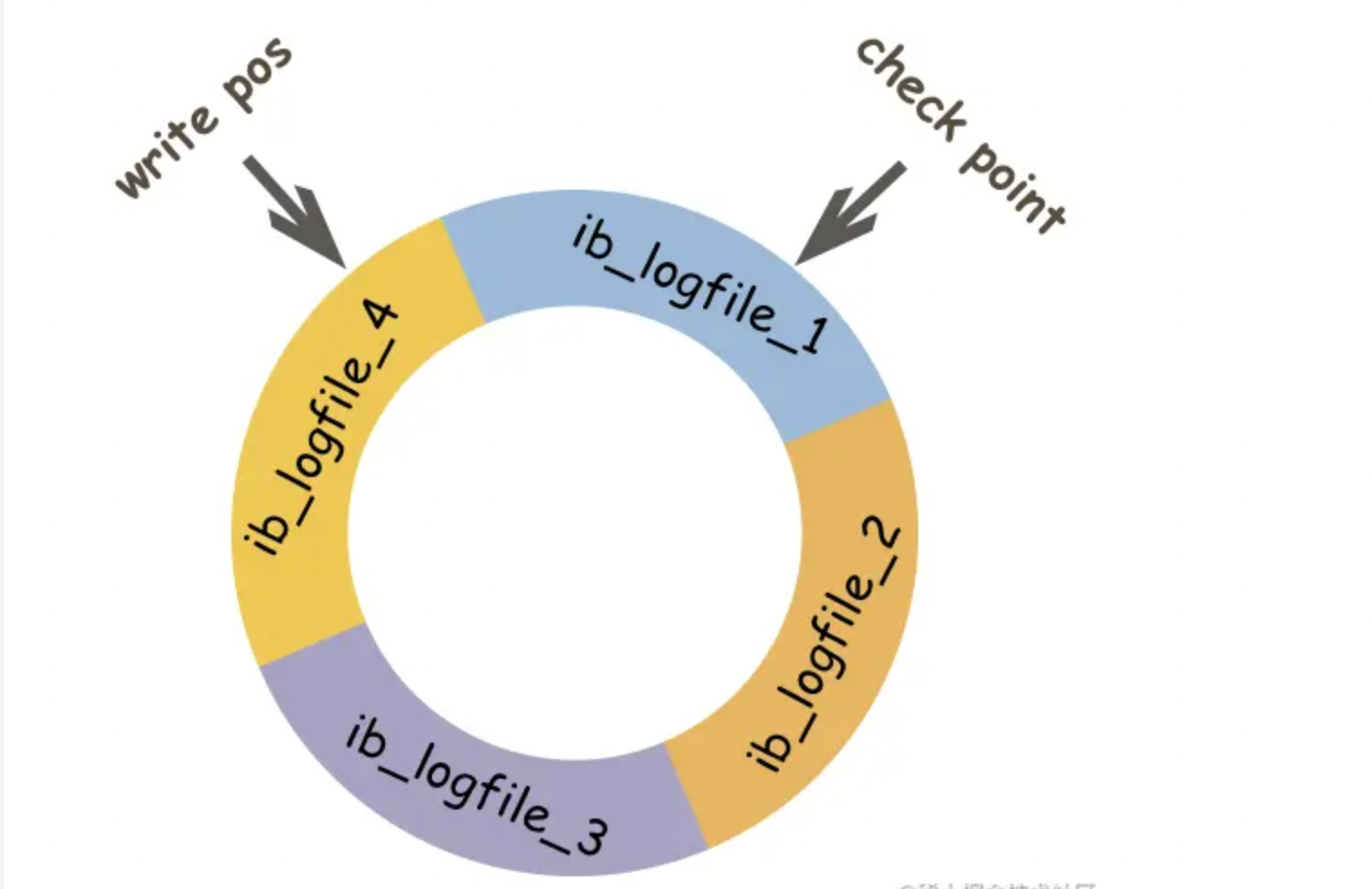
- 在innodb中,既有redo log需要刷盘,还有数据页也需要刷盘,redolog存在的意义主要就是降低对数据页刷盘的要求
- 虽然他在内存中有一部分,在磁盘有一部分,即便在磁盘中的内容他还是会循环覆盖哦,


undolog
redolog持久,那么undolog就是保证原子性
- undolog主要记录数据的逻辑变化,每个UPDATE语句,对应一条相反的UPDATE的undolog,这样在发生错误时,就能回滚到事务之前的数据状态
存储引擎
不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以 获得特定的功能 MyIsam , 2. InnoDB, 3. Memory, 4. Archive, 5. Federated
InnoDB 底层存储结构为B+树, B树的每个节点对应innodb的一个page,page大小是固定的,一般设为 16k。其中非叶子节点只有键值,叶子节点包含完成数据。 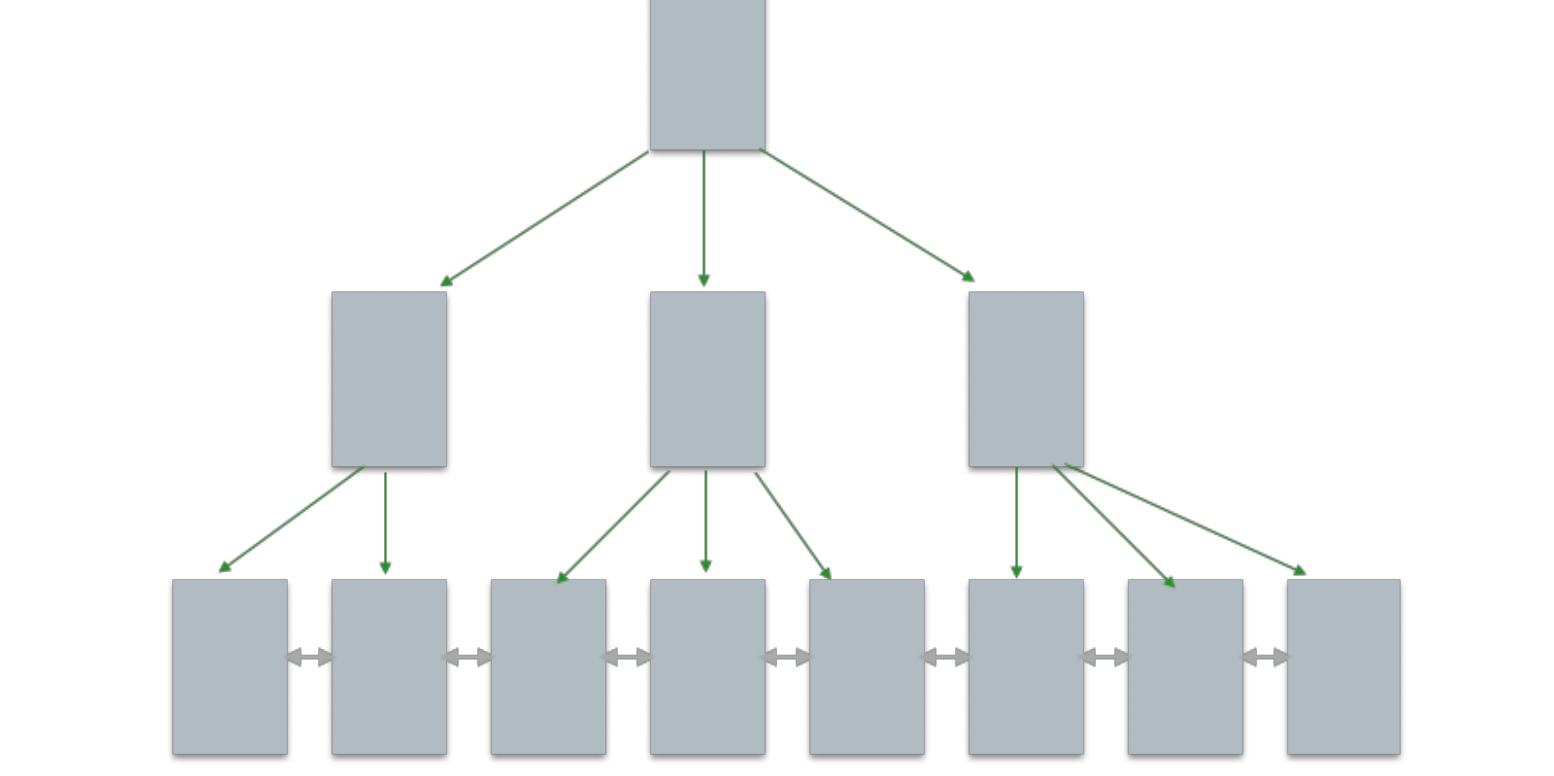
三范式
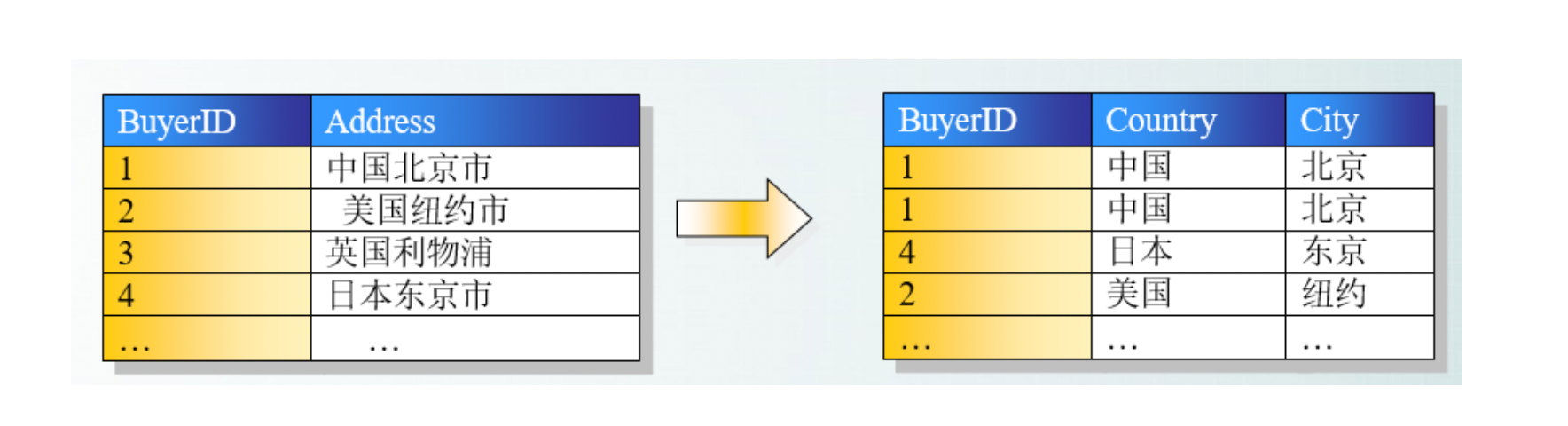
- 如果每列都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式(1NF)
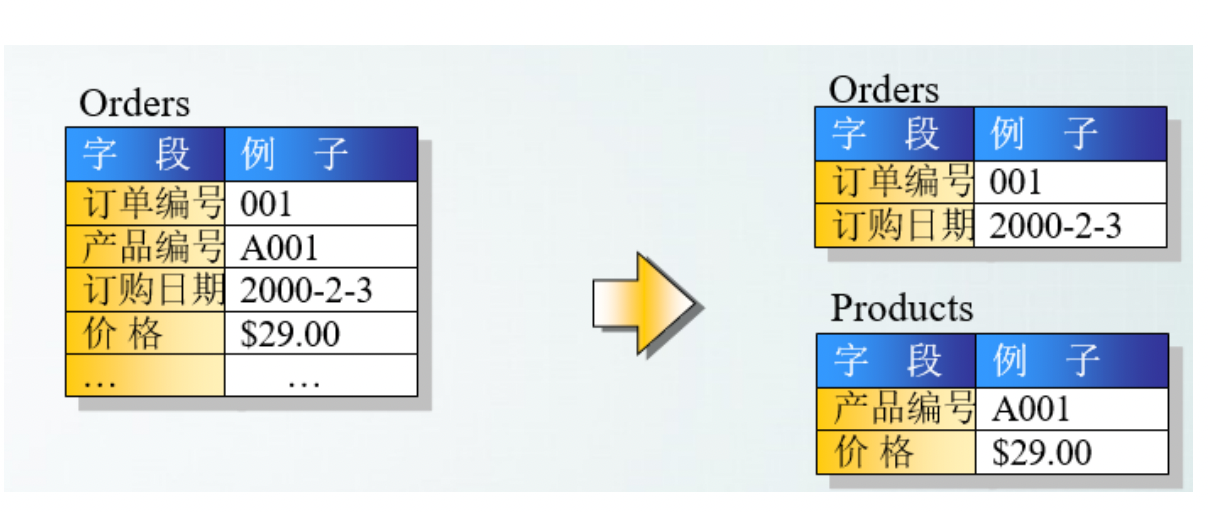
- 首先满足第一范式,并且表中非主键列不存在对主键的部分依赖。 第二范式要求每个表只描述一件事情。
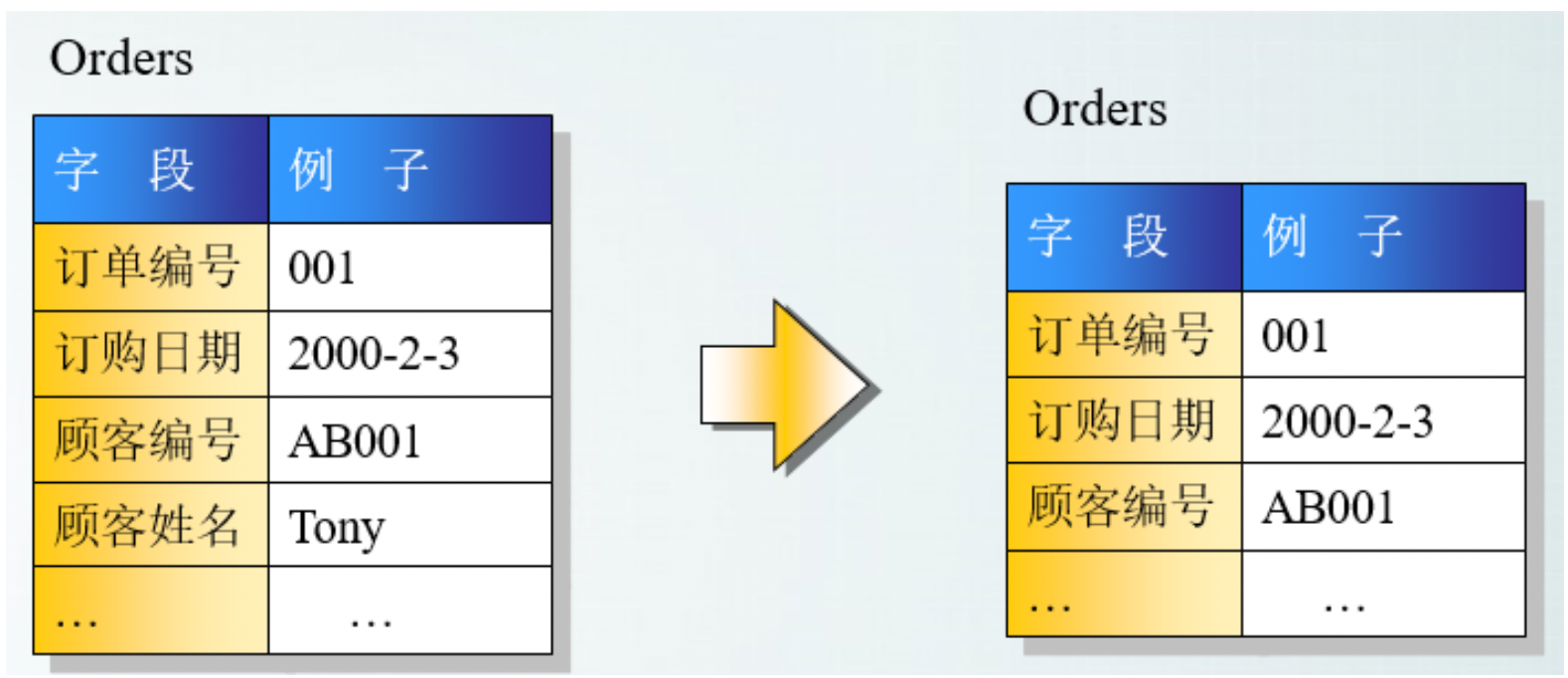
- 满足第二范式,并且表中的列不存在对非主键列的传递依赖。除了主键订单编号外,顾客姓名依赖于非主键顾客编号。
存储过程
一组为了完成特定功能的 SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它
触发器
触发器是一段能自动执行的程序,是一种特殊的存储过程,触发器和普通的存储过程的区别是: 触发器是当对某一个表进行操作时触发
分库分表,结合自己的业务理解
垂直区分(商品,交易,报表),水平区分(pt)
数据主从库同步
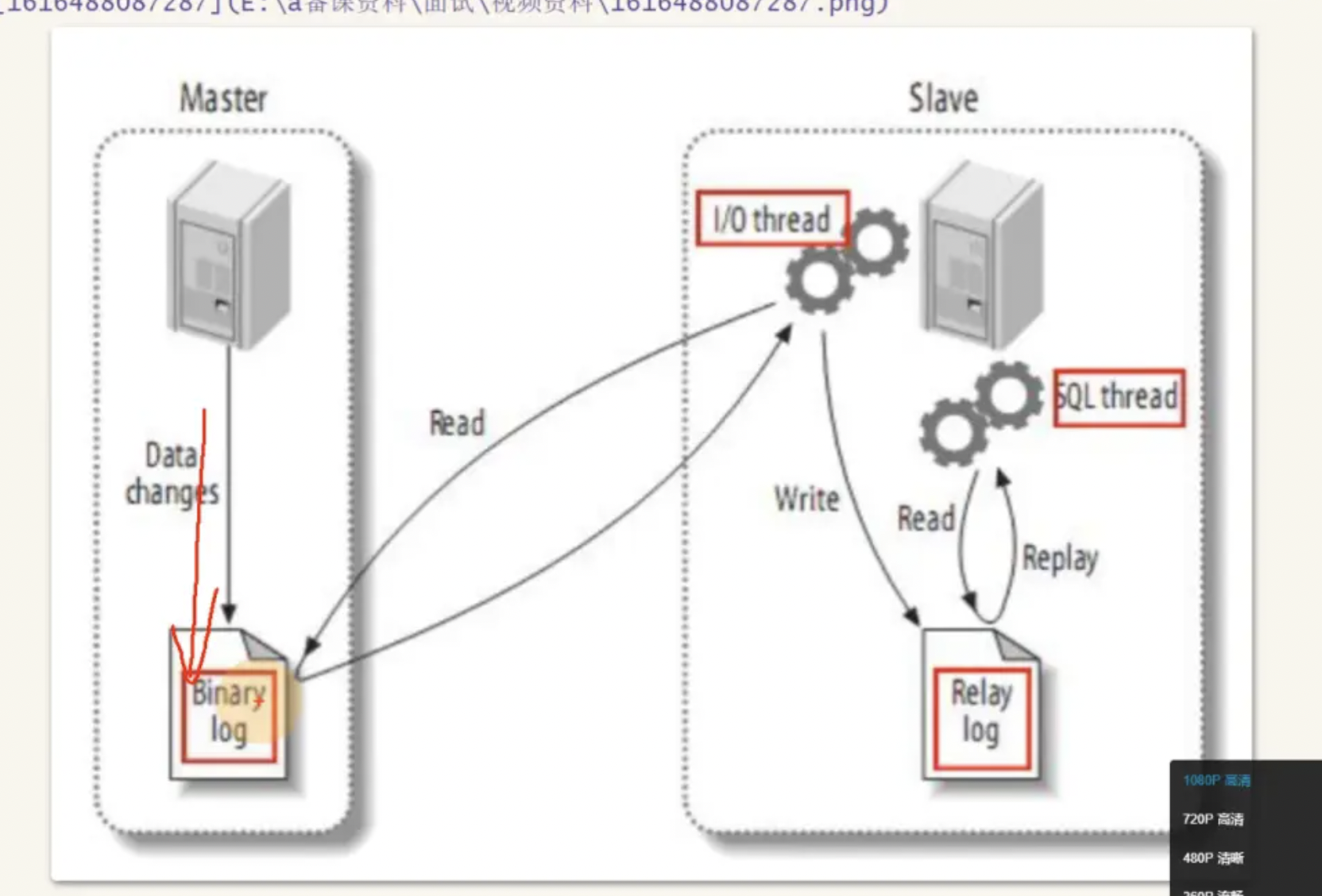 binary log 就是binlog
binary log 就是binlog
- 主数据库将数据写到binary log(二进制日志)基于语句或者基于行的二进制
- 用于记录对数据库进行的更改操作,它是 MySQL 的事务日志,记录了数据库的增删改操作,以二进制的形式存储在磁盘上。
- 从库的io线程读取主库的binary log
- 从库的io线程将数据读取到relay log(中继日志)
- 该日志不会持久化存储
- mysql线程将中继日志内容读取替换到本地数据库中
数据库锁
innodb支持的三种锁
- 行锁
- 锁直接加在记录上
- 间隙锁
- 当使用间隙锁时,InnoDB会锁住一个索引范围,确保索引记录的间隙不变;间隙锁是针对事务隔离级别为可重复读或以上级别而已的。
- Next-Key Lock
- 属于特殊的间隙锁,主要是间隙锁不会对索引范围两边的record加锁,但是next-key会
- 如果事务 A 锁定了键值范围 (10, 20],那么 Next-Key Lock 不仅会锁定这个范围的间隙,还会锁定键值为 10 和 20 的记录本身(区别在此)。
- 间隙锁是锁定索引记录之间的间隙。
- 当InnoDB扫描索引记录的时候,会首先对索引记录加上行锁(Record Lock),再对索引记录两边的间隙加上间隙锁(Gap Lock)。加上间隙锁之后,其他事务就不能在这个间隙修改或者插入记录。
- 何时能使用到间隙锁
- RR隔离级别下
- 查询条件必须有索引
- 间隙锁通过两个方面进行幻读的避免
- 防止间隙内有数据进行插入
- 防止在间隙外的数据通过update的操作移动到间隙内
数据库死锁??
mysql的流式查询
https://blog.csdn.net/liuxiao723846/article/details/130726967
- 普通:OOM
- 流:需要设置statement.setFetchSize(Integer.MIN_VALUE);
Statement statement = connection.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);- 过流式查询获取一个ResultSet后,通过next迭代出所有元素之前或者调用close关闭它之前,不能使用同一个数据库连接去发起另外一个查询,否者抛出异常
- 分批的从TCP通道中读取mysql服务返回的数据,每次读取的数据量并不是一行(通常是一个package大小)
- 游标查询:
- 在连接参数中需要拼接useCursorFetch=true;
- Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3307/test?useSSL=false&useCursorFetch=true", "root", "123456");
- ((JDBC4Connection) connection).setUseCursorFetch(true); //com.mysql.jdbc.JDBC4Connection
- 设置fetchSize控制每一次获取多少条数据
- 由于MySQL方不知道客户端什么时候将数据消费完,而自身的对应表可能会有DML写入操作,此时MySQL需要建立一个临时空间来存放需要拿走的数据。因此对于当你启用useCursorFetch读取大表的时候会看到MySQL上的几个现象:
- 磁盘空间飙升
- 在数据准备完成后,开始传输数据的阶段,网络响应开始飙升,IOPS由“读写”转变为“读取”。
- 客户端JDBC发起SQL后,长时间等待SQL响应数据,这段时间就是服务端在准备数
索引下推
索引下推 (Index Condition Pushdown,索引条件下推,简称 ICP),是 MySQL5.6 版本的新特性 它可以在对联合索引遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表 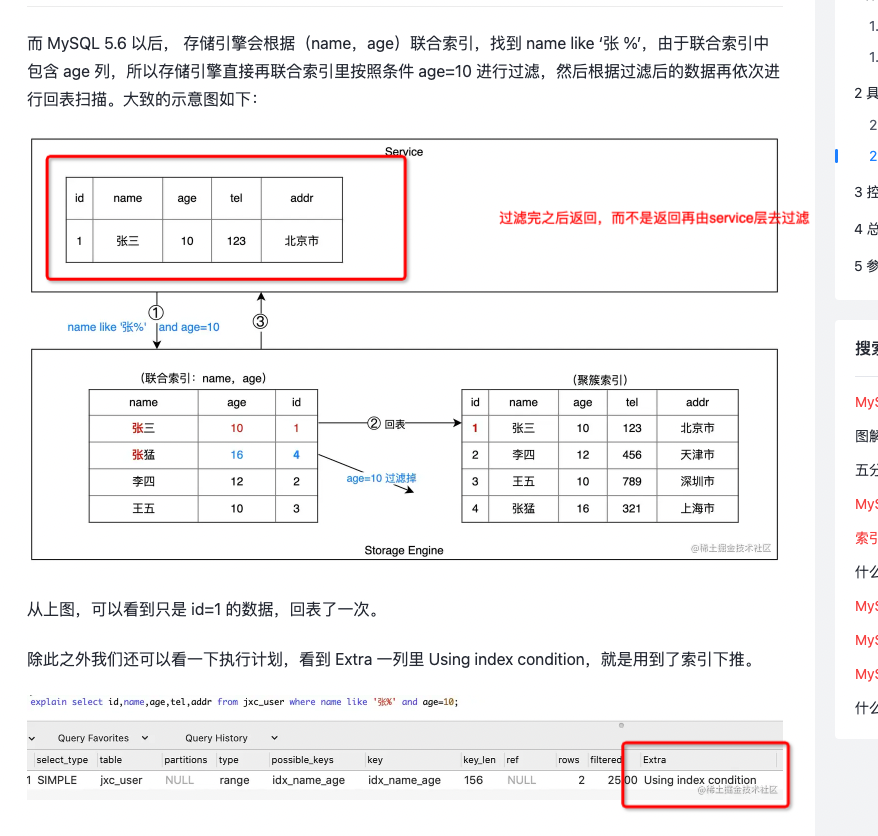
数据库锁: 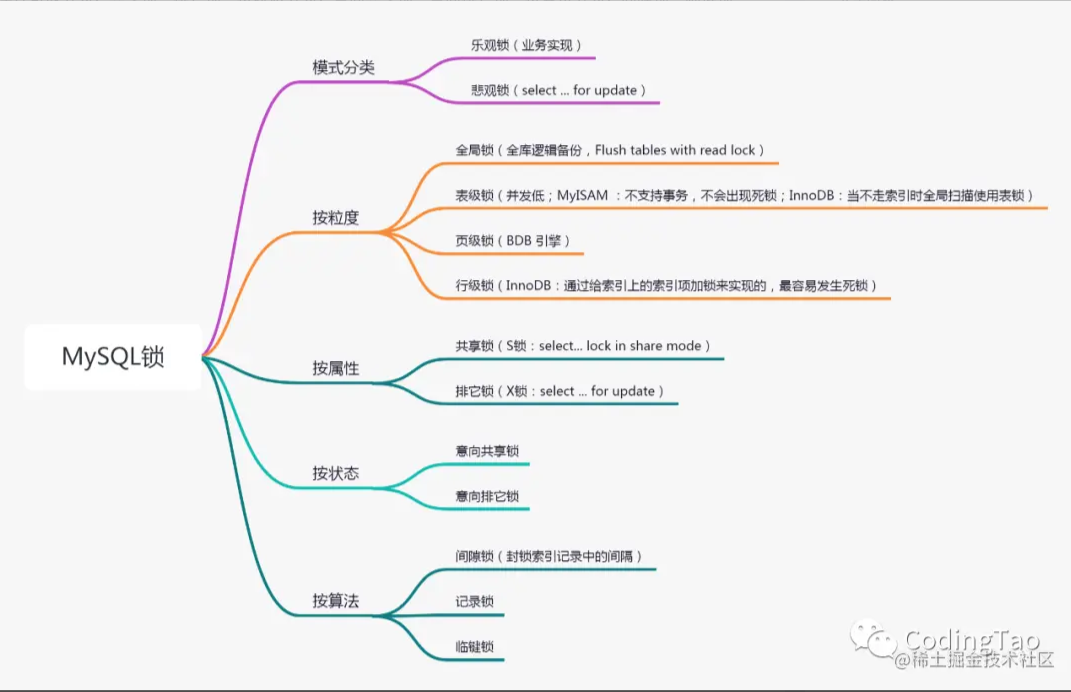
当前读:for update/insert/update/delete 都是要加锁的
- InnoDB 中的行锁的实现依赖于索引,一旦某个加锁操作没有使用到索引,那么该锁就会退化为表锁。
- 记录锁存在于包括主键索引在内的唯一索引中,锁定单条索引记录。
- 间隙锁存在于非唯一索引中,锁定开区间范围内的一段间隔,它是基于临键锁实现的。
- 临键锁存在于非唯一索引中,该类型的每条记录的索引上都存在这种锁,它是一种特殊的间隙锁,锁定一段左开右闭的索引区间。