hash表
散列表(Hash table,也叫哈希表)是一种查找算法,与链表、树等算法不同的是,散列表算法在查找时不需要进行一系列和关键字的比较操作 理想状态:散列表算法希望能尽量做到不经过任何比较,通过一次存取就能得到所查找的数据元素
存储位置和key之间的计算关系:h(key);
通过这个关系可以将hash方式分为以下几种
- 直接定址法
- h(key) = key 或 h(key) = a * key + b,其中 a 和 b 为常数。
- 平方取值法: 取关键字平方后的中间几位为散列地址
- 折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址。
- 除留余数法:h(key) = key MOD p p ≤ m
- 随机数法:
- 即:h(key) = random(key)
解决hash冲突的几种方法
- 拉链法:比如1.7的hashmap/1.8也算,但是算混合的
- 线性探测,发生冲突后往后找一个空余位置
- 再hash法,多个hash函数,一个 冲突采用另外的hash进行再hash
- 还有伪随机等算法,就是每次都不是按照数组大小进行hash,而是按照伪长度进行hash
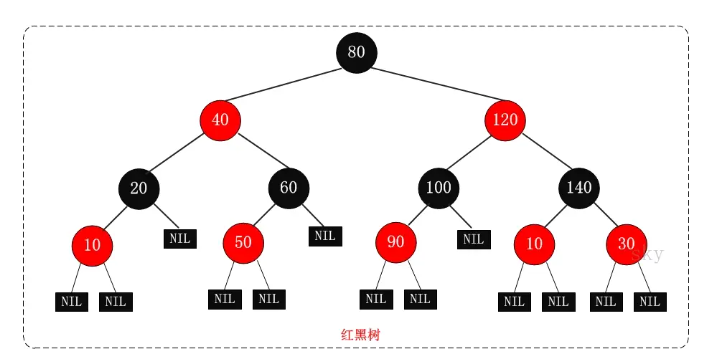
红黑树
红黑树的时间复杂度和相关证明
- 每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
- 补充不在5条特性中: 一棵含有n个节点的红黑树的高度至多为2log(n+1).
基本操作
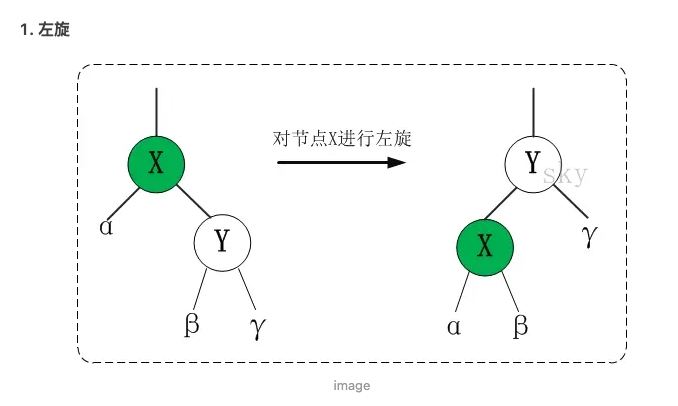
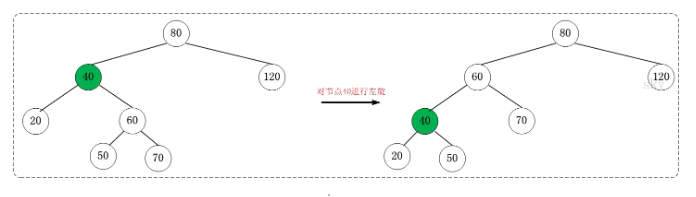
- 左旋
- (和平衡二叉树很像)
- 将右边节点的左孩子节点变为左节点右孩子节点,左节点的father变成右节点
- 右旋
- 跟左旋反过来,将左节点的右孩子节点变为右节点的左孩子节点,将右节点的father置为左节点
基本操作2添加add
概括:将节点插入;然后,将节点着色为红色;最后,通过旋转和重新着色等方法来修正该树,使之重新成为一颗红黑树 在5条特性中,只有4可能不符合,所以要针对不符合的场景做左旋或者有旋
- RB-Insert:插入节点Z,寻找父亲节点Y
- Y不存在,我为根
- Y存在小就左儿子,大就右儿子
- 上色红色
- 开始旋转:RB-INSERT-FIXUP
- RB-INSERT-FIXUP
- 步骤1:
- case:当前节点的爸爸叔叔都是红色,爷爷是黑色
- 将爸爸和叔叔都变成黑色,将爷爷变成红色
- 现在异常的是爷爷了
- 当前节点变成爷爷,对爷爷进行处理
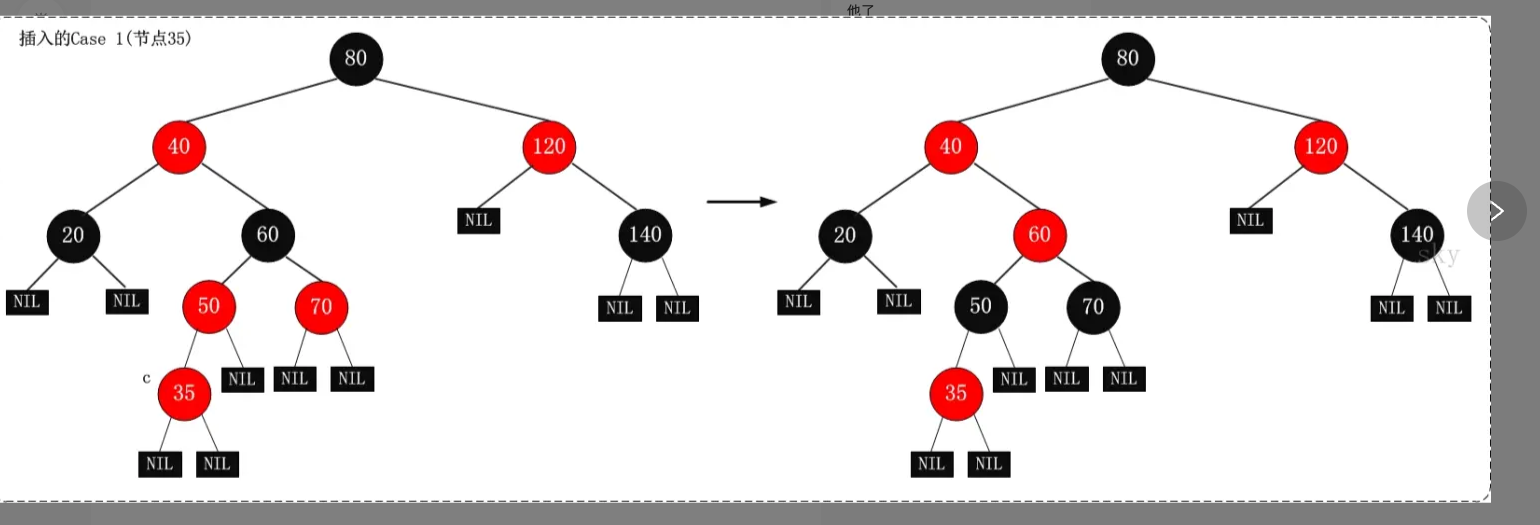
- 当前节点是60
- 步骤2:
- 当前节点父亲是红色,兄弟节点是黑色,并且是右儿子进行左旋处理
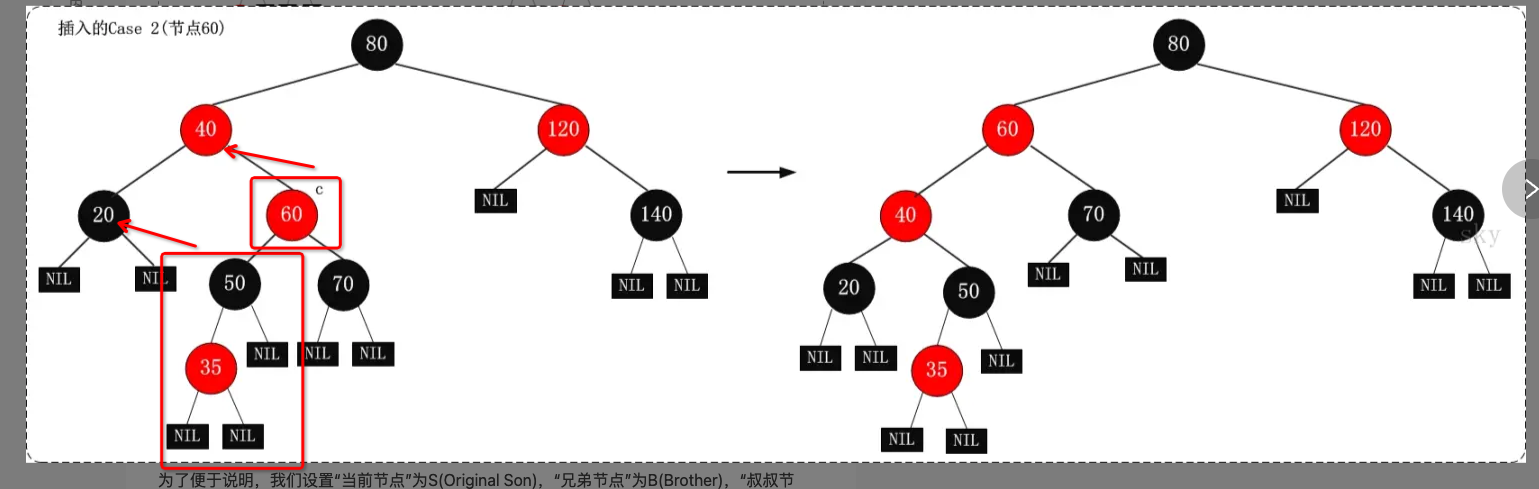
- 当前节点是40.将40进行了左旋
- 步骤3:
- 当前节点的父亲是红色,兄弟是黑色,当前节点是红色且为父亲节点的左孩子
- 将父亲变为黑色,爷爷变成红色
- 以红色的爷爷作为当前节点进行右旋
- 爷爷是80,80变红了右旋
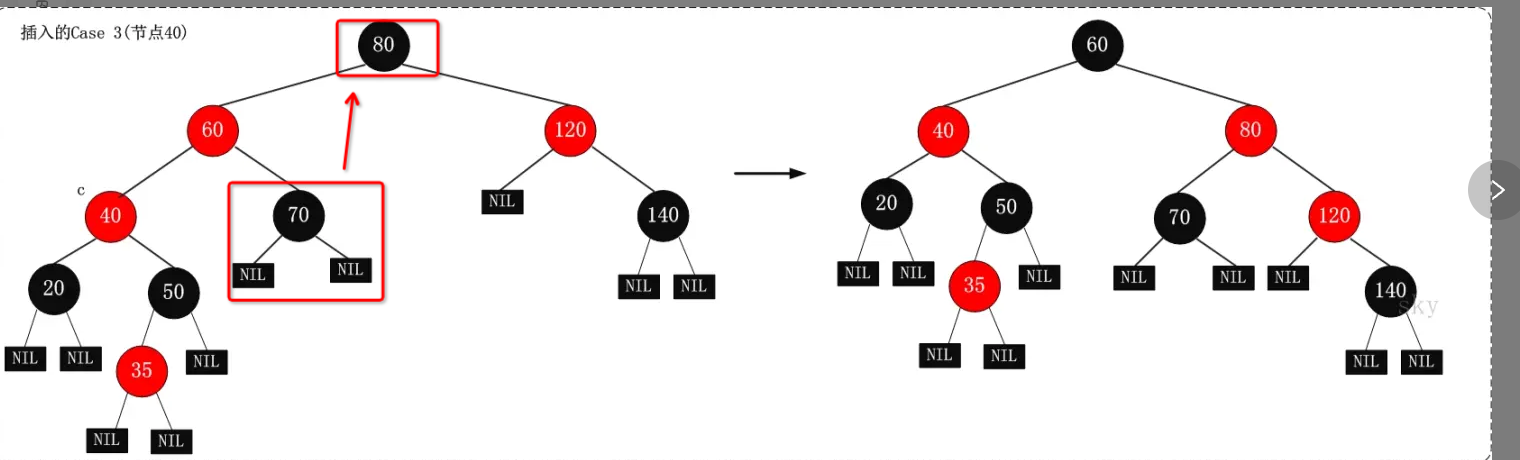
- 120变为当前节点,重复步骤2
- 步骤1:
基本操作:delete
没看 直接总结
- 被删除节点没有儿子,即为叶节点。那么,直接将该节点删除就 OK 了。
- 被删除节点只有一个儿子。那么,直接删除该节点,并用该节点的唯一子节点顶替它的位置
- 被删除节点有两个儿子。那么,先找出它的后继节点;然后把“它的后继节点的内容”复制给“该节点的内容”;之后,删除“它的后继节点”。
- x 是“红+黑”节点。直接把 x 设为黑色,结束。此时红黑树性质全部恢复。
- x 是“黑+黑”节点,且 x 是根。什么都不做,结束。此时红黑树性质全部恢复。
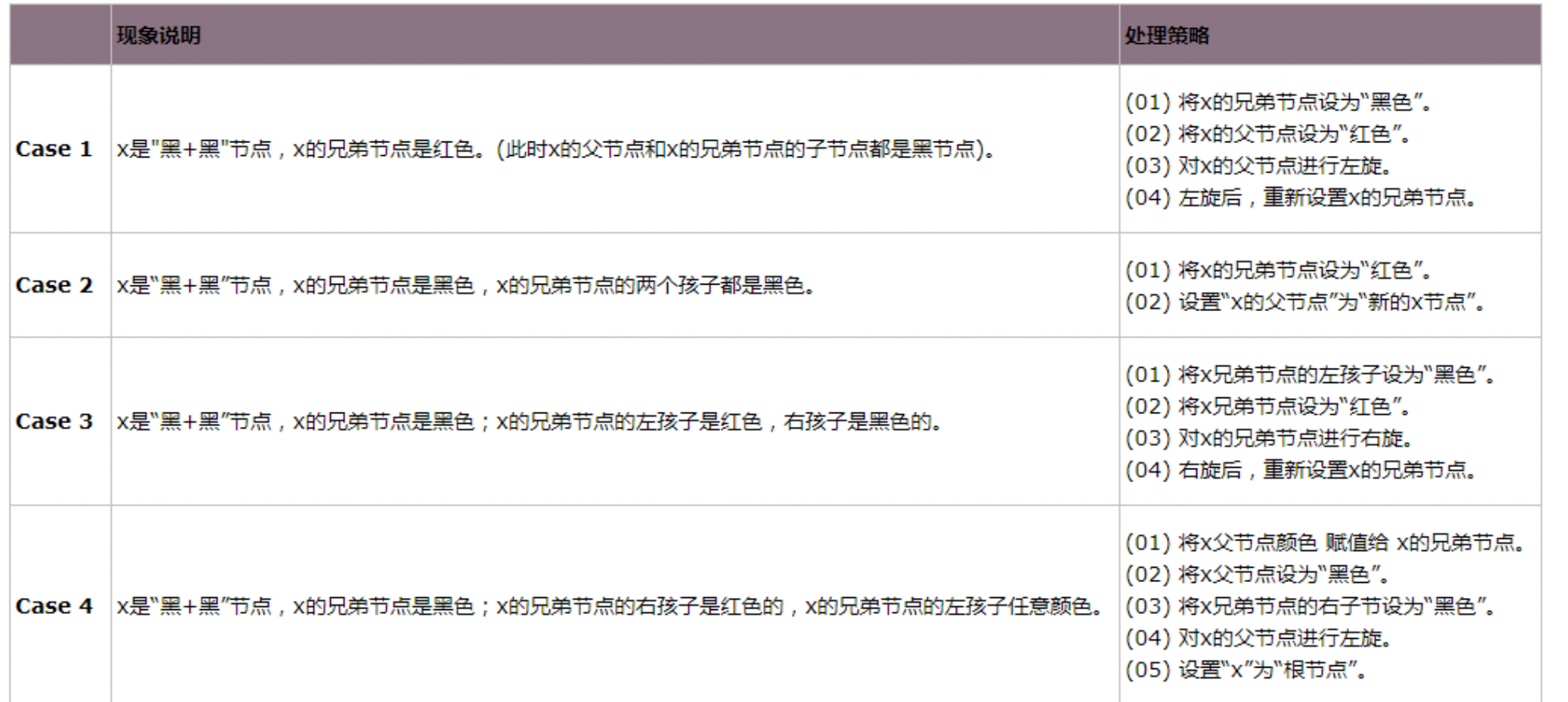
- x 是“黑+黑”节点,且 x 不是根 这种情况又可以划分为 4 种子情况
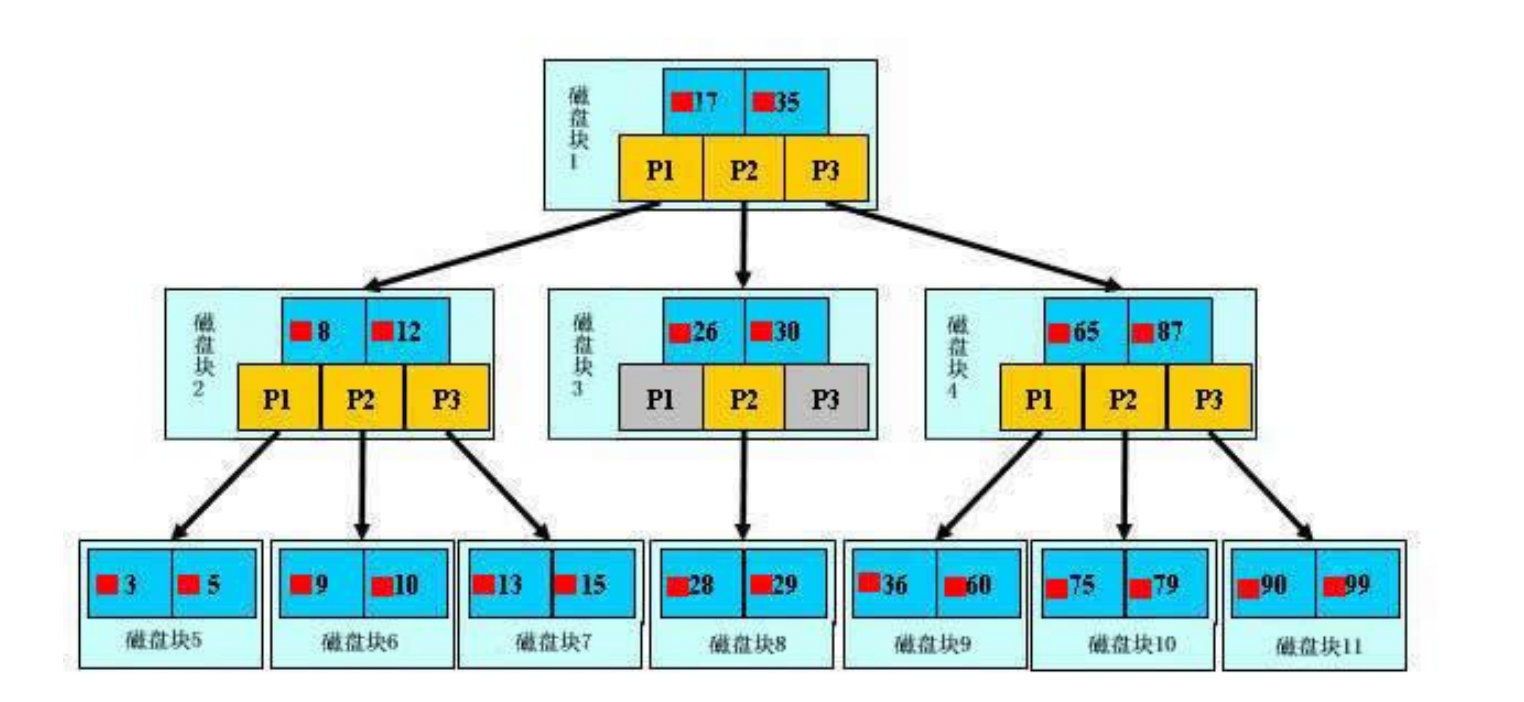
b树
举例子:一棵 m 阶的 B-tree (m 叉树)
- 树中每个结点至多有 m 个孩子
- 除根结点和叶子结点外,其它每个结点至少有有 ceil(m / 2)个孩子;ceil:向上取整
- 若根结点不是叶子结点,则至少有 2 个孩子
- 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息
- 每个非终端结点中包含有 n 个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中
- Ki (i=1...n)为关键字,且关键字按顺序排序 K(i-1)< Ki。
- p为指针
- 关键字的个数 n 必须满足: ceil(m / 2)-1 <= n <= m-1。
- ceil(m / 2) 向上取整
- ceil(m / 2) 向上取整
b+
- b+树的关键字会比b树多
- b+树为:m
- b树为 ceil(m / 2)-1 <= n <= m-1。
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。(B-tree 的非终节点也包含需要查找的有效信息)
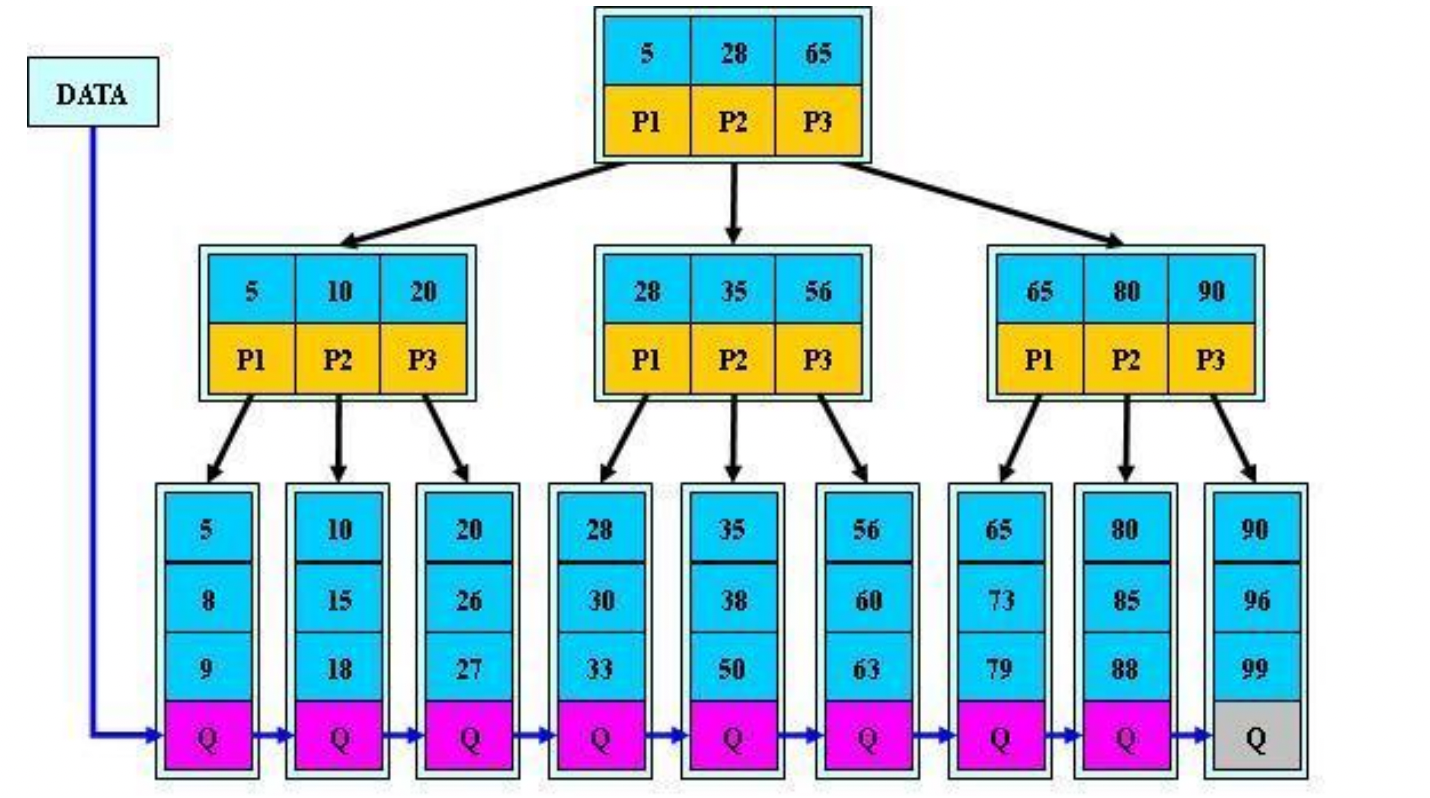
为什么是B+做索引不是B做索引
- B+树空间利用率更高,可减少I/O次数;B数的非叶子节点存储了数据及指针;B+树的非叶子结点只存储了指针,如果一个磁盘存储数据是16byte,指针一个2bytes,数据一个2bytes;那么一个9阶的b树要扫描所有中间节点需要282,要两个盘存储,而B+树只要扫描一个盘
- 查询效率更加稳定:b+树所有数据都存在叶子结点,所以每次查询数据都要稳定的找到叶子结点。再查询数据